We use a client-side rate limiter (Aperture) to limit and prioritize gpt-4 requests, but we still struggle to tune it properly. How are tokens being estimated from the character count?
This is what we have in the code -
estimated_tokens: Math.max(
tokens + TOKEN_MARGIN,
// `max_tokens` is the response token count
ALL_MODELS[modelVariant].maxModelTokens -
ALL_MODELS[modelVariant].requestTokens,
// sometimes OpenAI does character count / 4
// see - https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
(message.length + this.systemMessage.length) / 4,
)
Note that in the above snippet, the tokens variable holds the token count estimated via tiktoken.
Our scheduler is working only because we make the requests go back to the scheduler a few times in case we hit the rate limits, and it would be better to avoid entirely hitting the rate limit with precise tuning. Any guidance on how the rate limiter is actually working would be greatly appreciated.
As in the other thread where you made the same post, the blocking of inputs is quite temporally-separated from the inputs that accumulated that rate. You need consideration of the tokens received back when they are received to really get a handle on it, and also look at the headers of rate to know your decreasing limit and reset times.
Thanks for the response. This warranted a separate post as others might run into the same issue with client-side rate limiters.
Working with headers alone is not feasible –
We are doing global scheduling + prioritization of requests across multiple containers, so we need to know globally how much limit we have left and wait times.
Rate limit headers alone provide little value when doing global scheduling as it’s unclear what the wait time for retries should be.
It would help us to understand the token bucket dynamics that OpenAI has so that we can mimic them in our client-side rate limiter with some breathing room.
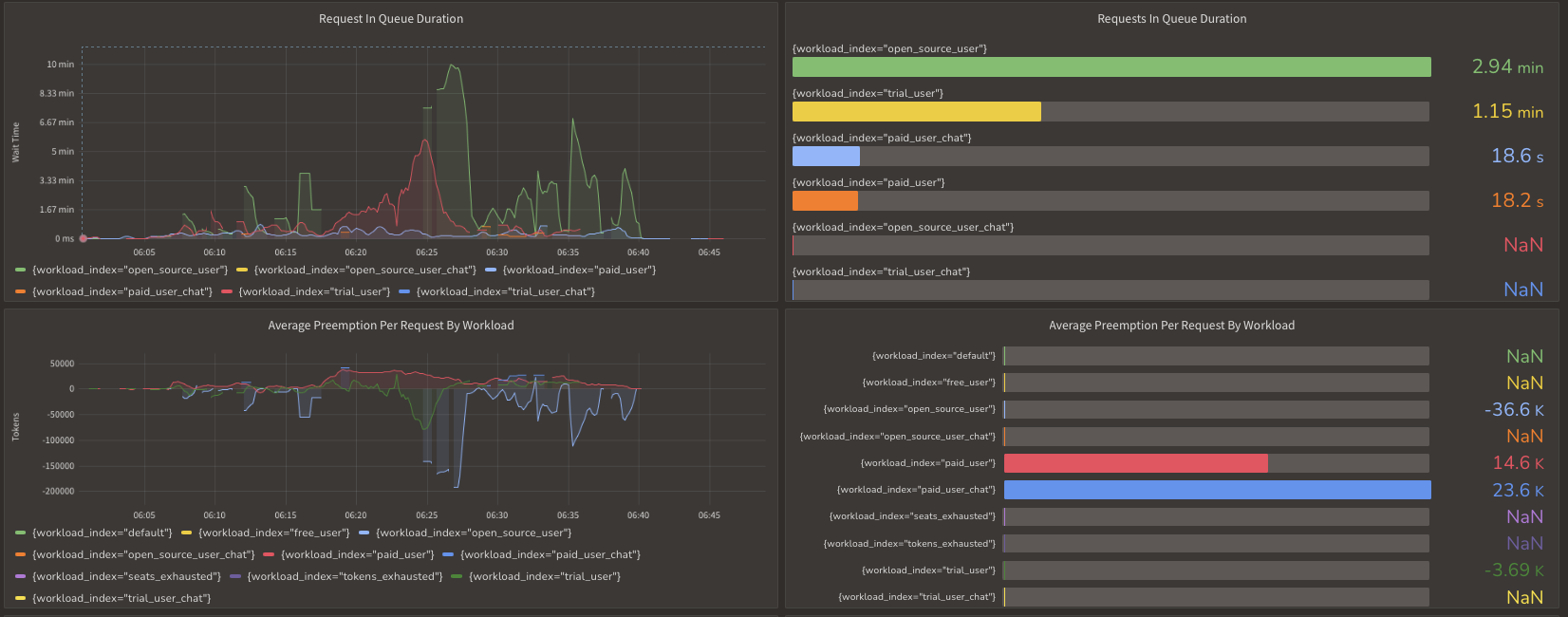
Below is a screenshot that shows prioritization of different workloads that are accessing gpt-4.
TLDR: I would like to know how OpenAI estimates tokens from character counts? character_count / 4 is not working for us, and we overshoot the limit most of the time despite lowering the burst capacity in case OpenAI is doing sub-minute quantization.
From the docs, “As a rough rule of thumb, 1 token is approximately 4 characters or 0.75 words for English text.”
So your formula looks correct.
But you may need to adjust it, I recall that more tokens are used for non-English text.
Also, not sure that the formula is 100% correct now with the new 100k tokenizer, 4:1 ratio goes all the way back to the original 50k tokenizer, so maybe the formula estimate needs updating?
Additionally: for your request, input prompt is estimated, while max_token is directly used to determine if that particular request gets a block.
Now, that has to do with calculating the blocking, but is the correct token count for both input and generation what actually counts against you when the generation job is done? Then you have to do the same tokenizer counting, or else you’ll get slammed with blocks when someone tries Chinese at 2-3 tokens per character.
Shouldn’t take more than a few requests of set token size to see if your header count goes down by that exact amount of the API response and reported usage, or is still estimated.
I ran some experiments today by printing the OpenAI rate limit headers and correlating with our rate limiter logs.
I strongly believe that the OpenAI rate limiter is adding both the estimated token count of the prompt and the max response tokens that we send in the request. This behavior is different from the guidance - " Your rate limit is calculated as the maximum of max_tokens and the estimated number of tokens based on the character count of your request."
Most probably the formula for rate limit estimation is - (character_count)/4 + max_tokens
Little late to the party here, but since you bumped it:
character_count / 4 is not the OpenAI guidance. it’s a rule of thumb for laypeople to wrap their head around. you gotta use tiktoken or something if you want any sort of accuracy. I’d correct that on your blog post too. You even linked to the page where it says exactly that, I guess you didn’t scroll far enough.
This is regarding the rate limiter OpenAI has deployed within CloudFlare. They don’t run a tokenizer (e.g. cl100k_base) while calculating rate limits. Tokenization happens after the rate limits are enforced. If you are using actual token calculation to figure out rate limits then you will be quite off.
PS: We tried working with tokenizer (tiktoken) and our limit estimates were quite off. With character_count/4 that is pretty much exact.
We are pretty sure, as we are seeing precisely the same number being returned to us in the x-ratelimit-remaining-tokens header that we are tracking on our client side. Note that because chat completion takes several seconds, the headers are several seconds stale - i.e., the time estimate in x-ratelimit-reset-tokens is several seconds outdated info.
We haven’t switched to Azure - we heard from others that it’s been tough for anyone to get rate limit increases for gpt-4 and gpt-4-32k right now with Azure.
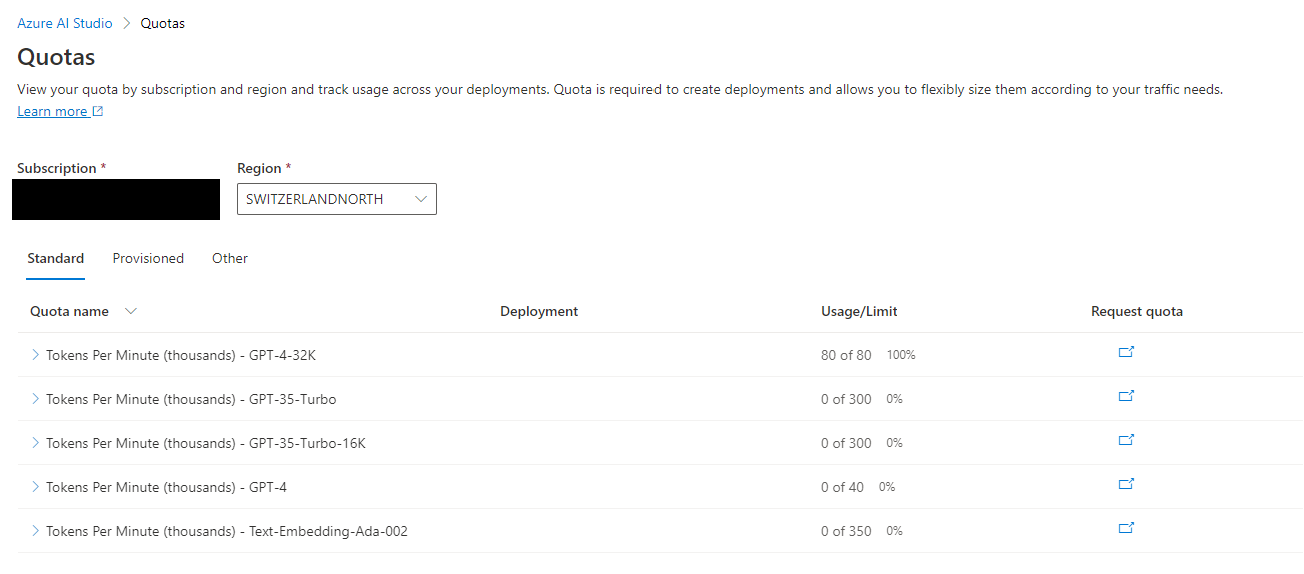
On Azure, when setting quotas it says “View your quota by subscription and region and track usage across your deployments. Quota is required to create deployments and allows you to flexibly size them according to your traffic needs.”
I just checked and tried to set this up (didn’t load test though, to be fair)
I still have the base quotas, didn’t request any increases (only requested model access)
There are 6 regions running gpt-4 currently.
with 80 k GPT-4-32K TPM each, you apparently really can set the limits independently.
so that theoretically gives you almost half a million GPT-4-32K TPM as a baseline.
plus another quarter million GPT-4 TPM
in addition, you can also enable dynamic quota for each deployment
Dynamic quota allows a deployment to take advantage of available capacity in service. If capacity is available, we will dynamically increase your quota and receive higher throughput. We will not decrease your quota below the set amount.