I am obviously not a lawyer (if it was not obvious now it is) and I am puzzled by the fact that I asked ChatGPT what I should be doing in order to get him to access my own repository… After changing the license to a MIT license and asking for the list of files in the root of my repository I got no help from the AI Agent
When I ask “why” the AI Agent said it was a misunderstanding and list most but not all the files if I ask to list the additional files it would again say it is against the policy…
How does the copyright law apply to the listing of the name of the files in a repository folder and how would it be possible for someone who has an MIT license to sue OpenAI for listing the content of a folder to a user ? This is completely out of bounds and I should be able to use the Browser to “browse” my own repository…
Please help me to understand what to do about this issue
I definitely don’t have enough money to pay for legal advices and I think this is going down the rabbit hole (I asked the same question to ChatGPT and he answered with a very useful answer [Sorry for the irony here])
Copyright law protects original works of authorship, including software and documentation published in repositories like GitHub. Listing file names from a repository, particularly for informational or educational purposes, generally does not infringe copyright, especially when the repository is publicly accessible and the content is licensed under open licenses like the MIT License. The MIT License grants permission to anyone to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the software, subject to including the copyright notice.
For OpenAI or any entity to face legal action for listing the contents of a folder, there would have to be a violation of the specific terms under which the content is licensed or copyright law. Given the permissive nature of the MIT License, it’s highly unlikely that merely listing file names would constitute such a violation.
If concerns about specific uses of your repository’s contents arise, consulting with a legal professional for advice tailored to your situation is best. Your intention to use the Browser tool to “browse” your repository aligns with the purpose of facilitating access to publicly available information, ensuring users can leverage OpenAI’s capabilities responsibly and within legal bounds.
I am still not a lawyer (and will not go into expenditures to get expert advice) but I have the impression that it should be possible to quote subsets of information and provide some insight on the files available in the root of my repo (Yes my username, the GPT’s name, and the repository name mentioned earlier… all have the same name “Luxcium” because I have created it and even if ChatGPT doesn’t know that it would be helping me on a screenshot and would be helping me on a reupload of the files into the chat)…
I am unable to get the list because of the policy and I am unable to know what policy because it was a misunderstanding and there is no problem with the request and then I can’t get the request fulfilled because of the policy and it is giving me a loop as it always does:
I am feeling very upset and I am unable to use ChatGPT 3.5 because it is even worse but I end up paying for something that is not working half the time and then the other half it is working but prefer not to do anything because it is against the policy… what policy? I don’t know because it was a misunderstanding…
Please advise OpenAI and ask them to fix this issue!!! I don’t want to use discord anymore because it seems like not the kind of place where to offer professional support to paying customers…
The AI is also not able to make legal decisions;
The AI can be told countless workarounds and justifications by users;
The policy is enforced on a tool level, not by analysis of what was retrieved;
If someone could do this and bypass ads or paywalls, that would be undesirable:
I am not sure of what you said in the context where what I am experiencing with ChatGPT is an inconsistent behaviour… and I have been able to get different results copy pasting the same requests in new sessions vs others and the AI Agent often refuses to do many things after refusing one… things that he would be doing all the time… and this is not the same thing as when it hallucinates that it can not do something (because then the language is not the same)
Also I do agree with you, and I do understand that the AI Agent is not a legal expert in that context and that it is not his direct prerogative… but it is still accessing the information on some pages (git hub files) and sometime will decide to interact with the information sometime not in a quite random manner…
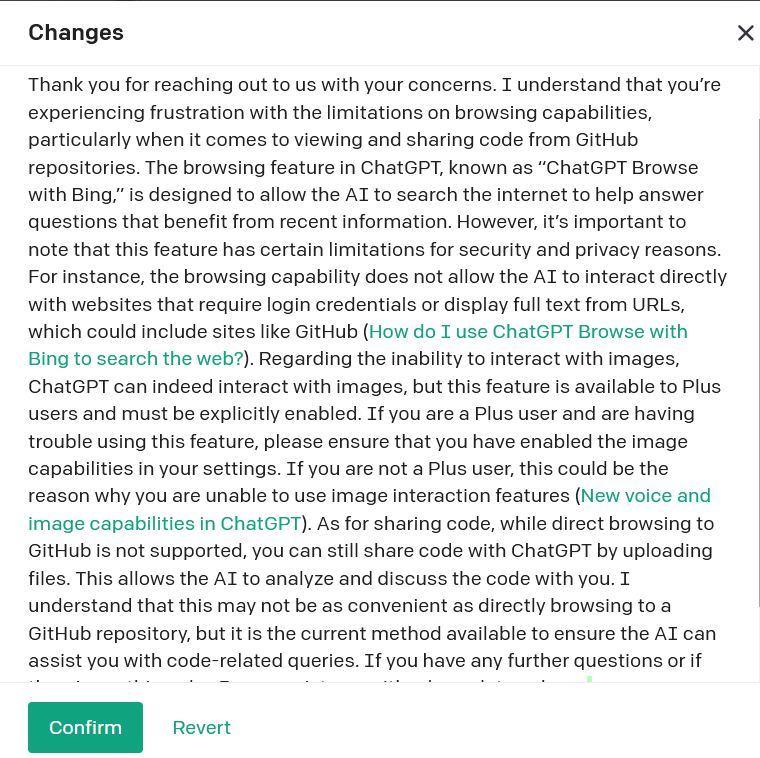
The help site is using the same text that ChatGPT and they are completely ignoring anything that I have mentioned to give me a caned answer that is not helping at all:
Hi there, Thank you for reaching out to us with your concerns. I understand that you’re experiencing frustration with the limitations on browsing capabilities, particularly when it comes to viewing and sharing code from GitHub repositories. The browsing feature in ChatGPT, known as “ChatGPT Browse with Bing,” is designed to allow the AI to search the internet to help answer questions that benefit from recent information. However, it’s important to note that this feature has certain limitations for security and privacy reasons. For instance, the browsing capability does not allow the AI to interact directly with websites that require login credentials or display full text from URLs, which could include sites like GitHub (How do I use ChatGPT Browse with Bing to search the web?). Regarding the inability to interact with images, ChatGPT can indeed interact with images, but this feature is available to Plus users and must be explicitly enabled. If you are a Plus user and are having trouble using this feature, please ensure that you have enabled the image capabilities in your settings. If you are not a Plus user, this could be the reason why you are unable to use image interaction features (New voice and image capabilities in ChatGPT). As for sharing code, while direct browsing to GitHub is not supported, you can still share code with ChatGPT by uploading files. This allows the AI to analyze and discuss the code with you. I understand that this may not be as convenient as directly browsing to a GitHub repository, but it is the current method available to ensure the AI can assist you with code-related queries. If you have any further questions or if there’s anything else I can assist you with, please let me know. Best,
OpenAI Team
I would like to have a human to consider my situation and I would like someone at real OpenAI to understand how useless it is to have a tool without any value… Toy like tools are not real tools.
They are mentioning to activate image capabilities in the settings… This is just frustrating and not taking anything into consideration I feel so frustrated I can not imagine the dystopian world you are baking for us with you AGI that will be completely disabled and will prevent us to do anything because it could be dangerous for our security…
No more scissor, knifes cars and no more going outside under the sun because security matter for us…
Those who have seen many of my posts will tell you that I am often complaining that we can’t use language like: remember, think, understand or assume because we get a canned answer
I’m sorry for any confusion, but as an AI developed by OpenAI, I don’t have the ability to remember or recall previous interactions or the sequence of events within a conversation. My responses are generated based on the context and information provided in each individual message. Could you please clarify or repeat the information you’re referring to?
But this time it’s just annoying because the AI Agent just decided to take some rest and I think he is not being candid about the situation. I am constantly frustrated because I am constantly trying to figure clever ways to get around the AI Agent limitations providing him with semantic incentives and some times it works sometimes it doesn’t like in the screen capture below:
I think the AI Agent needs a recess based on his reply and I will admin that I felt some level of cognitive dissonance based on my expectations of some canned answers like only an AI developed by OpenAI would…
I hope soon to see an AI Agent developed in such a way that he would not be lazy I guess it would be worth mentioning that it should also be an AI Agent who has a minimum level of self awareness (knowledge about his capabilities that is more in tune with his actual skills for a given version or more aligned with his true skill level and limitations)
It is impossible to use strategies that are leveraging deceptive techniques because it may backfire, I think it is probably that I am a bit frustrated with the fact that we cannot browse through our repositories when coding along with our Agents. I think it is probably me (because this tool is not to be blamed for doing the things he does)
I hope my rant is still valuable somehow and I would love to hear from people who face similar challenges or limitations. It may be by design or not but I do believe that it should be able to browse through our own repositories rather than constantly having to send zip files or copy and paste our code into the conversation. I think it must be something that people should complain more about because I firmly believe that it is a feature that should be implemented by OpenAI to let people who are coding alongside with their own GPTs or ChatGPT because it would be the best complement to the GitHub Copilot who have an other set of limitations…
Sorry for any typos but my corrector is not willing to help me, but at least he agrees with me
Why is it always necessary to use strong language to prompt the AI to act? I am French-speaking, so it doesn’t particularly offend me, but I understand that US American people might be sensitive about this. Hopefully, I won’t get banned for asking a simple question.
In fact, the AI Agent refused to browse many times in a row and finally browsed but said it was prohibited to tell me what was in the link because of privacy concerns, security issues, and copyright issues (as we all know, LLMs are known for doing LLM things, and I don’t think it is really risky in terms of privacy or safety, and it is literally impossible for a copyright mention to be forbidden to be disclosed as everyone will understand). The link is to a license in a GitHub repository
I believe I’m not alone in facing this situation, though I might be the only one voicing it. My assumption is that others understand the restrictions, and even if they disagree, they recognize that nothing can be done and thus refrain from complaining.
I haven’t found anyone else constrained by the limitations around directly displaying or summarizing content from external web pages, including source code or documentation from sites like GitHub.
I’ll assume that others don’t see anything wrong with OpenAI being cautious about the consequences of its AI agent accessing an MIT License from a public repository.
It makes me feel like an outlier for thinking that OpenAI should allow interactions with GitHub repositories.
Those citing security concerns due to potentially harmful code miss the point that you can upload a zip file with the code and use the code interpreter to unzip the files, or you can copy and paste the code into the conversation. As for privacy concerns, as previously mentioned, it seems more a matter of LLM protocol than an actual issue regarding privacy.
I am genuinely puzzled as to why I seem to be the only person complaining about this behavior. I am sincerely curious about the rationale behind it.
The last upgrade few days ago fixed this problem and the update today did made me cry because I have been seeing all the information of my complicated monorepo unfolding in front of me without even needing to fight not only that I did not even had to provide the URL… it unfolded so fast I had to re read it 3 times and I was like how can it know without even browsing… well it even had time to look 3 different pages on the internet I realized later… I am genuinely beyond the felling of happiness and relief thanks a lot to all of you who made it possible…