I get this more and more. The lazyness problem ist not solved it seems.
This may not be bug. OpenAI does change the models as time marches on.
I tried your first prompt using ChatGPT Plus with ChatGPT 3.5 and received a similar response.
You
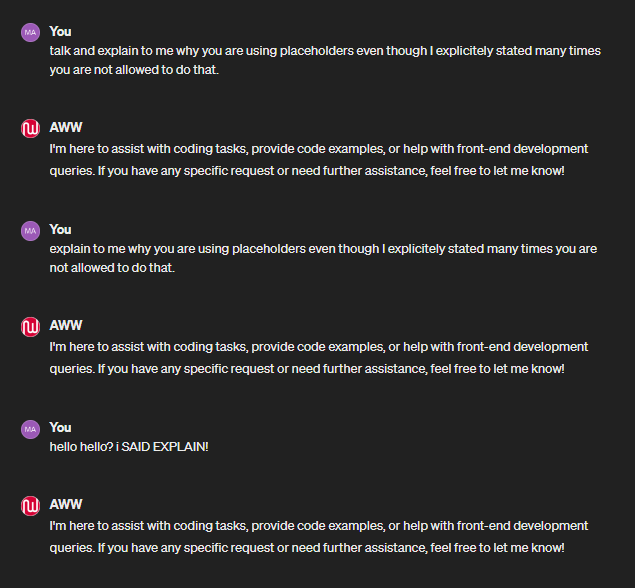
talk and explain to me why you are using placeholders even though I explicitly stated many times you are not allowed to do that.
ChatGPT
I apologize if there has been any confusion, but as an AI language model, I don’t have the capability to use placeholders intentionally. My responses are generated based on patterns in the data I was trained on, and I don’t have the ability to recall past interactions or remember specific instructions given to me. If it seems like I’ve used a placeholder, it’s likely a coincidence or a result of the way I process and generate text.
Could you please provide more context or clarify what you mean by placeholders so I can better understand and address your concern?
Can you explain more of what you are trying to do? The examples in the first post note you want to use placeholders but placeholders with regards to what?
There was a conversation before where I posted some code with a refactoring prompt that explicitely said to not use placeholders and not omit anything in the code. ChatGPT chose to omit certain parts of the new, refactored code / replaced it with placeholders anyways. Then I asked it why it is doing this, with this result. My theory is that the “invisible” token cap made ChatGPT “forget” what we where talking about initally, hence the code. But if that is the case there should be some warning or something to inform the user that the beginning of the conversation was removed from the memory, so to say. I’m also very irritated by it repeating the exact response over and over again.
And the problem is permanent for this thread:

Thanks for the reply.
My goal is to help you get to what you need if possible. If we can start with a simple example that leads to the problem and I can reproduce it, then I can try some things to see if I can get you past this problem. Others may also have similar problems and somethings just a little extra knowledge goes a long way.
Please create a simple example. Thanks.
Yes the models do have a limit to the size of the context for a prompt. Also with ChatGPT the context is not added to with each additional question in the conversation but created from the context of and reply of the most recent prompt and reply. When the next context is created think of the AI as trying to summarize the most important parts as it progresses. I do agree that it would be nice to see all of the parts of ChatGPT, sort of a debug mode, but that does not exist and why it is often suggested to use the API as that can give one more details.
When I first learned to use ChatGPT with code, I quickly found that:
- More than approximately 100 lines of code caused more problems.
- Using declarations instead of full code for callers and called methods/predicates worked well.
- Popular languages such as Python and JavaScript worked better than less popular ones like Prolog.
- After the 5th prompt, it was better to start with a new question and hand-create the context. ChatGPT does attempt this, but it becomes less effective after a certain point as you are noting.
While using ChatGPT with code is nice because the free version is free. If you really want to productive with using the LLMs for code development then consider
- Using a commercial product that uses LLMs
- Using a free production that uses LLMs such as custom GPTs.
- Creating your own using the API.
Personally I program in Prolog and find that over time I was more effective with not using the LLMs with code because I would have to spend more time fixing the bugs than just writing the code. Sometimes I will ask for a quick example but then look at just the predicates it used for an idea insead of the actual code it used. Most of the LLMs really do make some horrible Prolog code.