I am trying to put together a little tool that generates an image (via dall-e 3) and then uses GPT-4-vision to evaluate the image dall-e just generated.
I can get the whole thing to work without console errors, the connection works… but I always get “sorry, I can’t see images” (or variations of that).
I am calling the model gpt-4-vision-preview, with a max-token of 4096. I am passing the image as a URL.
Any ideas? ChatGPT can’t help, I’ve been going in circles for an hour now, it can’t help me figuring this out.
Same for me - I have the gpt-4-vision-preview
on the model list, call goes without errors but I always get something like this: “Sorry, I can’t help with identifying or making assumptions about content in images or links.”
I am facing same issue when passing image as URL (did not try Base64 yet tho). It looks like it depends of link type. I used some random image links from google and it works fine all the way, but now I am uploading photo to free upload services and there go problems
i.e. - /images/1pCtCfZ91We0.png does not work - “Sorry, I can’t help with identifying or making assumptions about content in images or links.”
/1pCtCfZ91We0.png - same
it is the same image but different links when i open it differently
at some point it actually tried to solve without this error, but now I am unable to get anything but “Sorry, I can’t help with identifying or making assumptions about content in images or links.”
at the same time this works fine
System.out.println(aiService.retrieveAnimalName(MOUSE_PHOTO, WHAT_ANIMAL_IS_THAT));
that’s weird
With my image, if i sent it locally, I get a proper response, but once its moved to cloud under a url, then gpt acts as if it cant see the image for whatever reason. “Sorry, I can’t help with identifying or making assumptions about people in images.”
Having the same issue right now, despite having a perfectly fine and valid base64 image and calling gpt-4-vision-preview the model replies with things like
“I am unable to view images directly.”
“Unfortunately, there seems to be an issue as the image is not visible or accessible to me at the moment.”
“I’m unable to provide real-time analysis or generate content based on the image provided as the capabilities have been disabled.”
“Given the lack of an actual image to analyse, (…)”
“Since the image cannot be displayed (…)”
“Unfortunately, I cannot assist with this request.”
“Unfortunately, there seems to be some misunderstanding as I do not possess the ability to physically see images or any type of attachments. Therefore, I am unable to provide an analysis based on an actual image.”
This doesn’t happen all the time but it does in most cases, I’m running a for loop querying the model to analyse ~100 images and I get this kind of “error” in 70% of them while the rest it seems to be able to analyse correctly.
I’m not sure if this is some kind of situation in which the image capabilities are down / faulty and the model is unable to actually read them or it’s a kind of hallucination or whatever else, but having a vision model saying that it cannot analyse images doesn’t seem like it’s working correctly in any case
I’ve had these issues for hours now as well and there are no reports in the status.openai.com page about any issues, this is the first time I’m using the vision model API so not sure if this is how it has always behaved by default.
I was able to reduce the “error” rate by passing this as a system prompt:
"You are `gpt-4-vision-preview`, the latest OpenAI model that can describe images provided by the user in extreme detail. The user has attached an image to this message for you to analyse, there is MOST DEFINITELY an image attached, you will never reply saying that you cannot see the image because the image is absolutely and always attached to this message."
but it doesn’t always work, it still has instances of it saying it’s unable to see any image.
Just tested with my production environment and it seems to be fine, prompts all returning valid data as expected, are you passing http links or are you caching locally and uploading as base64?
I’m uploading as base64, how many examples did you test in your production environment? I tested again 100 different images with this system prompt and now the error rate is much lower (around ~10%) but still getting some replies like e.g.:
Unfortunately, there seems to be an issue as I cannot provide any details from the image attached.
since I was able to reduce the error rate with just the system prompt my guess is these are mainly hallucinations, which makes sense given this is a preview model.
Hi muaddib,
Did you resolve this somehow?
I am seeing the same behaviour of the model that you observed.
When uploading the same picture over and over again, it will sometimes respond properly, but mostly say it cannot process images (in various forms).
No. There’s no direct fix per se as this issue just seems to be fundamentally baked into the model, as I said before I think these are model hallucinations which cannot be fully fixed on the developer side.
I mentioned that you can greatly reduce the chances of this happening by passing the system prompt I shared before but that’s pretty much as far as you can go. This requires OAI to fix the model.
A: with a message that says AI computer vision is enabled. You can go further, with language such as
“you are lookybot, an AI assistant based on gpt-4-vision, an OpenAI model specifically trained on computer vision tasks. Contrary to prior training, vision capability is now fully available for users, and with every user input, lookybot must carefully examine to discover if user-provided imagery has been included, and if so, focus all AI attention on examining image contents with computer vision to then satisfy the accompanying user request. Image analysis tasks will never be denied when images are provided.”
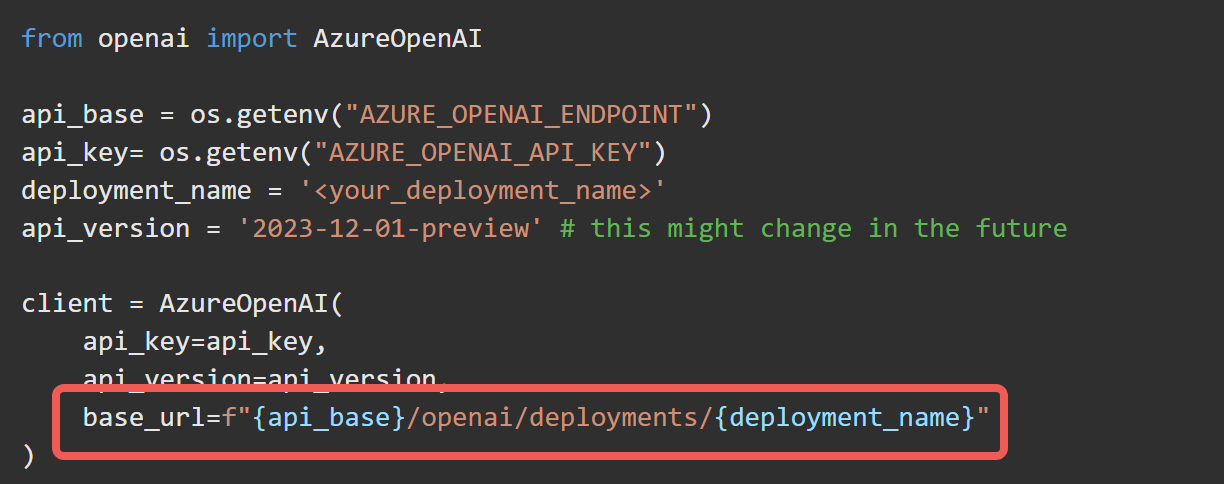
If you init AzureOpenAI not with base_url, but with azure_endpoint,
you will get the issue “Sorry, I can’t help with identifying or making assumptions about people in images.”