Hello everyone, I’m currently working on a project where I need to extract parameters from a user input. For this, I am utilizing function calling. However, I’m facing a challenge as my parameter list, or “enum”, is quite extensive, containing around 780 items. Additionally, each request I make is about 10,000 tokens. In this scenario, what would be the best practice? Should I consider fine-tuning or something else? Looking forward to your insights and suggestions. Thank you!
Yes. 10,000 tokens minimum input per message is insane.
If you can fine-tune and reduce your prompt to <3,000 tokens you are spending less.
Fine-tuning lets you get more out of the models available through the API by providing:
Higher quality results than prompting
Ability to train on more examples than can fit in a prompt
Token savings due to shorter prompts
Lower latency requests
First though, what are you doing that requires 780 different values?
Fine-tuning won’t help; you’ll just increase likelihoods, but I expect no constraints to be enforced. The AI will be an expert on inferring other responses similar to those shown in examples of employing context-less items.
If the user data input is on the smaller side and isn’t burdening the possibility of multiple calls, you could conceive how a lookup function might better work.
For example, give the AI a task: find a trademark class from 80 different categories, each with an extensive list of codes. You’d want the AI to be able to browse those categories, enter the most likely, and find what it is looking for, thus avoiding the entirety of mind-boggling documentation.
The primary goal of my project involves working with a set of files that are extensively categorized. Each file is labeled with a year and falls under a hierarchical categorization system - 15 main categories, 30 subcategories, and an additional 780 sub-subcategories. These categories help in organizing the data, which also includes numerical values representing the amount of damage. My task involves extracting this data using function calls and then filtering it from the database.
In response to your example about the AI task: I am relatively new to the API aspect, so please excuse any misunderstanding on my part. As I mentioned in my previous message, my project requires extensive and precise filtering. I need to follow a clear and exact path. I’m wondering why fine-tuning would not be effective in this case. Wouldn’t training with all my files make a difference?
Besides categories, I could also potentially use names for navigation, which would offer more flexibility. However, accuracy is crucial here. For instance, if a user searches for ‘red bicycle’, the AI should not retrieve something like ‘red bicycle clock’.
Essentially, what I am looking for is to use GPT to filter through 70,000 files. How can I achieve this in the most efficient way?
Fine-tune is training the AI on example output. Here you’ve shown the AI exactly what it should do in one particular case:
messages
system: You are a data extractor, finding parameters within user input.
user: I went to the baseball game, and got sick on a hot dog. Caught a ball though.
assistant: {“topic”: “baseball”}
I can train an AI with thousands of such examples. The AI will be very adept at outputting topics in a JSON that relate to the input. However, the AI will have no problem writing “orbital dynamics” or “parapsychology”, because you’ve trained it to find the most likely answer.
Placing the entire list from which it can answer in context, especially as a function enum list, is the best technique by far. You then can just explore multi-step methods where the whole list can be avoided.
1 Like
You have options
The idea behind fine-tuning is providing these large prompts & the model “learning” these values so your next prompt doesn’t cost as much as the function calling feature is essentially “baked in”.
Fine-tuning a model with function calling examples can allow you to:
–Get similarly formatted responses even when the full function definition isn’t present
–Get more accurate and consistent outputs
Another option is to build your own database. You can combine semantic searching along with keywords to form a very powerful hybrid search system without continuously spending lots of money on tokens. It’s also much easier to update. So if you are constantly updating/changing your labels this may be a better option.
You can still take advantage of function calling. You would just transfer the responsibility to your own database. More control (which can be a bad thing tho), and much less costs. You get the best of both worlds as well as you can use GPT to transform the query into something rich and relevant for your database.
I would recommend checking out weaviate and comparing these options. You can use it as a typical relational database as well as a vector database. Best of both worlds, it’s open source as well!
1 Like
The multi-step idea makes a lot of sense, thank you for it. I will inform you when I try it.
I don’t have much knowledge about semantic search, but here’s an idea that crossed my mind: Would it involve combining file names, dates, categories, and similar data into a single string, then embedding these and storing them in a database to perform similarity searches with help of GPT?
Apologies for my limited understanding on this topic, and sorry if this causes any inconvenience.
No worries.
You want to either describe these files, or just embed the contents. I don’t really know how you are structuring your chatbot, and what your ultimate goal is. So I’m really assuming a lot here.
This is an awesome example of what makes hybrid search so potent. Keyword search would over confidently rank red bicycle clock high close up with red bicycle.
Semantic search would knock red bicycle clock down a couple notches while maintaining or even boosting red bicycle.
But the issue with Semantic search is when, especially in your case a lot of documents are semantically similar (they are all damage reports, it could be that the only difference is a model #) the scores tend to blend together. That’s where keyword search kicks ass!

It’s right, but the confidence is too close for comfort.
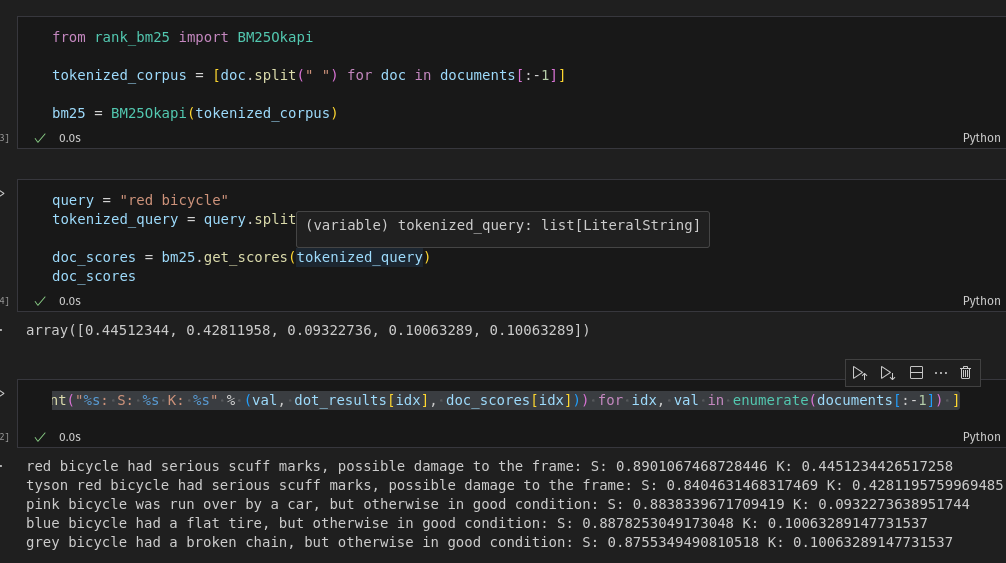
Ok keywords do much better to separate closely related documents

Bam, normalize the values and we have a very clear winner! I may have mathed wrong here. I do it a lot, but I think the idea is here.
You would place them in your database just as you would normally. You can describe your categories for filtering. No need to try and stuff as much of content into a single string. If your files don’t have ANY semantic OR keyword value you can just use your database as a pointer. You could use metadata to have the filename if you wanted.
1 Like
Another approach is to have the model first predict the function to call and then from the function make a second model call where you ask it to predict the category and sub-category to assign. That will reduce your schema size at the cost of a second model call anytime the function is called.
You are giving keyword and semantic search equal weight here, I believe? Is that the optimal strategy?
Also is it right “tyson red bicycle” is scoring so low in the hybrid? Not sure I get why the score ends up less than half and why “blue bicycle” gets a better score?!
Really interesting how the semantic scores are so poor for that example.
1 Like
I am, yeah. You could apply some weights at the step where I jammed it all into a list comprehension like a savage. Not sure about optimal. I guess it really depends on the content.
It’s (semantic) distance is greater to its neighbour than comparing the 2nd last item to 1st place by a crazy margin! 0.048 vs 0.014 !!! It definitely isn’t right, but at least the hybrid search tries to balance it. I imagine a big part is just how little variety of semantics is between them all. Then there’s just “tyson” thrown out of there. Bit of a curveball ![]()
1 Like
And what strategy to limit keyword search result array size?
A query with a common word is going to lead to massive search result which may not be practical in size.
Do we simply have to set a record limit and risk losing good semantic matches upon join?
Do we order things by how recent they were and simply lop off everything after a limit in the hope of picking up more relevant results?