The API playground does not have any image generation. If you talk to a chat API AI model, it can do nothing other than give fake links.
You didn’t say what happened when you ran that curl line. If at a persistent shell prompt, you should be given a URL to download the output by default - or receive an error. Download links last an hour.
then (besides the script in the third post) here is a “little” Python program from me to you, which runs locally on your computer and makes API calls. You’ll spend $0.02-$0.08 of your API credit balance per image, generating 1024x1024 images. (ChatGPT can detail Python setup for you, along with OpenAI’s quickstart in “documentation”)
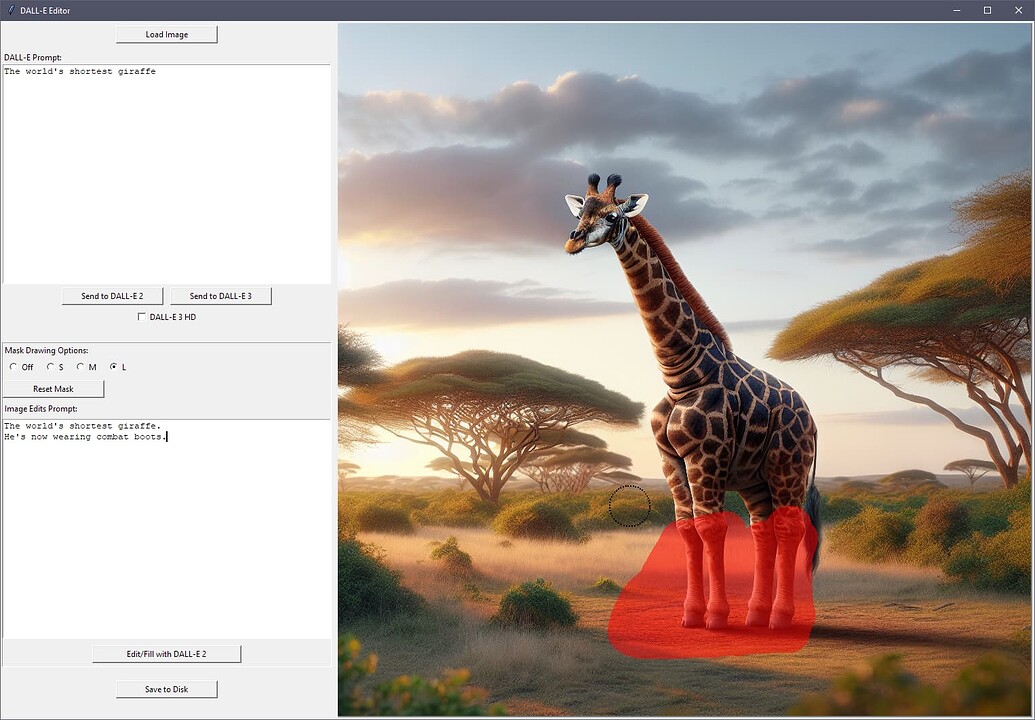
…and as you can see, the app allows you to mark areas for editing by DALL-E 2 and an image edits prompt, also.
(expand) DALL-E desktop editor - Python docs and code
DALL-E Editor: Friendly Introduction for Developers
Welcome to the DALL-E Editor—a practical, feature-rich application built in Python 3.11+, designed specifically to streamline interactions with OpenAI’s DALL-E 2 and DALL-E 3 APIs. This user-friendly GUI application leverages Python’s Tkinter library to simplify image generation, editing, and masking workflows, allowing quick experimentation with AI-generated visuals directly from your desktop.
The main focus is the edits endpoint for redraw and infill, at $0.02 per image, thus, this has a 1024x1024 image only.
(Documentation by AI)
Key Features and Capabilities:
1. Image Generation from Text Prompts
- Instantly generate high-quality images (1024×1024 pixels) using your descriptive text prompts.
- Choose between DALL-E 2 and DALL-E 3 models effortlessly.
- Easily toggle HD mode specifically for DALL-E 3.
2. Intuitive Mask Drawing Interface
- Draw precise masks directly on images for targeted editing or inpainting.
- Selectable brush sizes (Small, Medium, Large) to customize mask precision.
- Visual feedback through a semi-transparent red overlay, clearly showing masked regions.
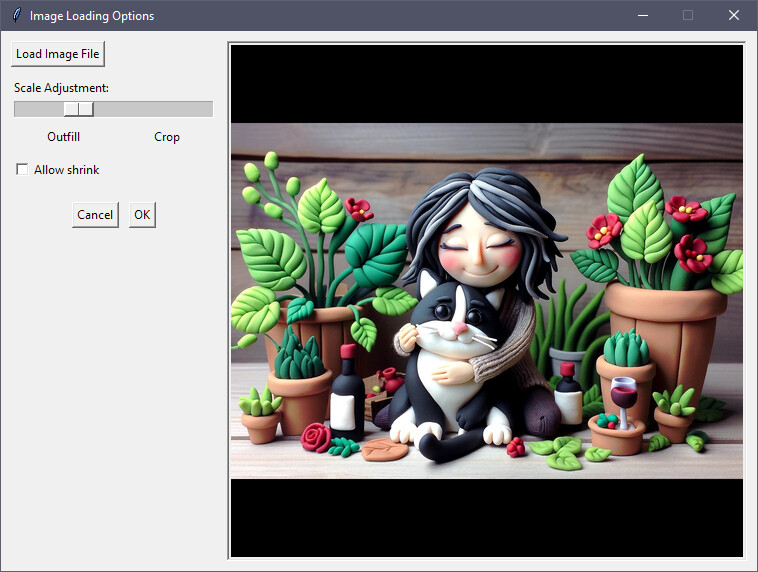
3. Dynamic Image Loading and Scaling
- Load images directly from your file system.
- Interactive slider for dynamically scaling images—choose between cropping to fit or filling (outfill) with optional shrinking allowed.
- Preview adjustments in real-time, allowing precise control of how images fit the target resolution.
4. Integrated Editing Workflow
- Send masked images along with editing prompts to DALL-E’s editing API endpoints seamlessly.
- Smart default prompts when performing outfill operations, simplifying repetitive editing tasks.
5. Robust Error Handling
- Automatically manages API errors gracefully, ensuring your workflow remains uninterrupted and clear error dialogs inform you promptly.
6. Convenient File Operations
- Easily save your generated and edited images to disk as standard PNG files.
Requirements:
- Python 3.11+
- Pillow: pip install pillow
- OpenAI Python SDK: pip install openai
- Funding your OpenAI account with credits to burn
- Set the environment variable OPENAI_API_KEY with your API key.
The code - name it dalle_editor.py or similar as a file.
#!/usr/bin/env python3
"""
dalle_editor.py
A tkinter GUI application that uses the new OpenAI DALL-E API endpoints to:
- Create a 1024×1024 image from a prompt (using images.generate)
- Allow the user to “draw” a mask using a pen tool (with selectable brush sizes) whose mask
is stored as metadata only.
- Display the image unaltered with a semi-transparent red overlay showing the mask areas for feedback.
- Call the edit endpoint (images.edit) using the original image and the mask (converted to a 32-bit PNG with an alpha channel).
- Save the unaltered original image to disk.
- ** Features:**
- Load an image from disk with dynamic scaling via a slider (and “Allow shrink” option).
- Two send buttons for DALL-E 2 and DALL-E 3 (with an optional “HD” checkbox for DALL-E 3).
- The editing UI is consolidated: the generation inputs are separate from the editing tools.
- Improved mask drawing: smooth continuous strokes are drawn instead of disjoint squares.
- A custom brush cursor (a dashed circle) shows the current brush size when drawing.
- Robust error handling for API calls (with timeout=40) that restores the previous image and shows an error dialog.
- When a loaded image’s mask exists (from an outfill operation), resetting the mask restores the originally loaded mask.
Requirements:
- Python 3.11+
- Pillow: pip install pillow
- OpenAI Python SDK (with new images.generate / images.edit methods): pip install openai
- Set the environment variable OPENAI_API_KEY with your API key.
"""
import asyncio
import base64
from io import BytesIO
import threading
import tkinter as tk
from tkinter import filedialog, messagebox
import time
import math
from PIL import Image, ImageTk, ImageDraw
# Import the new OpenAI API client (which supports async usage).
from openai import AsyncOpenAI
# =============================================================================
# Async API Wrapper Class
# =============================================================================
class DalleAPI:
def __init__(self):
self.client = AsyncOpenAI() # Uses the OPENAI_API_KEY env variable
async def generate_image(self, prompt: str, model: str = "dall-e-3", **kwargs) -> Image.Image:
image_params = {
"model": model,
"n": 1,
"size": "1024x1024",
"prompt": prompt,
"response_format": "b64_json",
}
image_params.update(kwargs)
image_params["timeout"] = 40
response = await self.client.images.generate(**image_params)
b64_data = response.data[0].b64_json
image_data = base64.b64decode(b64_data)
image_file = BytesIO(image_data)
new_image = Image.open(image_file).convert("RGB")
return new_image
async def edit_image(self, base_image: Image.Image, mask_image: Image.Image, prompt: str) -> Image.Image:
base_bytes = BytesIO()
base_image.save(base_bytes, format="PNG")
base_bytes.seek(0)
mask_rgba = Image.new("RGBA", mask_image.size, (0, 0, 0, 255))
mask_rgba.putalpha(mask_image)
mask_bytes = BytesIO()
mask_rgba.save(mask_bytes, format="PNG")
mask_bytes.seek(0)
response = await self.client.images.edit(
image=base_bytes,
mask=mask_bytes,
prompt=prompt,
n=1,
size="1024x1024",
response_format="b64_json",
timeout=40,
)
b64_data = response.data[0].b64_json
image_data = base64.b64decode(b64_data)
image_file = BytesIO(image_data)
new_image = Image.open(image_file).convert("RGB")
return new_image
# =============================================================================
# Image Load Dialog Class with Dynamic Scaling and "Allow shrink" Option
# =============================================================================
class ImageLoadDialog(tk.Toplevel):
def __init__(self, parent, file_path):
super().__init__(parent)
self.title("Image Loading Options")
self.parent = parent
self.resizable(False, False)
self.grab_set() # Modal
try:
self.orig_image = Image.open(file_path)
except Exception as e:
messagebox.showerror("Error", f"Could not load image:\n{e}", parent=self)
self.destroy()
return
self.scale_var = tk.DoubleVar(value=0.0)
self.allow_shrink_var = tk.BooleanVar(value=False)
self.processed_image = None
self.processed_mask = None
main_frame = tk.Frame(self)
main_frame.pack(padx=10, pady=10)
# Left controls
controls_frame = tk.Frame(main_frame)
controls_frame.grid(row=0, column=0, sticky="ns")
# Right preview
preview_frame = tk.Frame(main_frame, width=512, height=512, bd=2, relief="sunken")
preview_frame.grid(row=0, column=1, padx=(10,0))
preview_frame.grid_propagate(False)
load_btn = tk.Button(controls_frame, text="Load Image File", command=self.load_new_file)
load_btn.pack(pady=(0,10), anchor="w")
slider_label = tk.Label(controls_frame, text="Scale Adjustment:")
slider_label.pack(anchor="w")
slider = tk.Scale(controls_frame, variable=self.scale_var, from_=0.0, to=1.0,
resolution=0.01, orient="horizontal", showvalue=0,
command=lambda v: self.update_processing(), length=200)
slider.pack(pady=(0,5))
labels_frame = tk.Frame(controls_frame)
labels_frame.pack(fill="x")
left_label = tk.Label(labels_frame, text="Outfill")
left_label.pack(side="left", expand=True)
right_label = tk.Label(labels_frame, text="Crop")
right_label.pack(side="right", expand=True)
shrink_checkbox = tk.Checkbutton(controls_frame, text="Allow shrink", variable=self.allow_shrink_var,
command=self.update_processing)
shrink_checkbox.pack(pady=(10,10), anchor="w")
btns_frame = tk.Frame(controls_frame)
btns_frame.pack(pady=(10,0))
cancel_btn = tk.Button(btns_frame, text="Cancel", command=self.cancel)
cancel_btn.grid(row=0, column=0, padx=5)
ok_btn = tk.Button(btns_frame, text="OK", command=self.ok)
ok_btn.grid(row=0, column=1, padx=5)
self.preview_label = tk.Label(preview_frame)
self.preview_label.pack(expand=True)
self.preview_photo = None
self.update_processing()
def load_new_file(self):
file_path = filedialog.askopenfilename(
title="Select Image",
filetypes=[("Image Files", "*.png;*.jpg;*.jpeg;*.bmp;*.gif"), ("All Files", "*.*")],
parent=self
)
if file_path:
try:
self.orig_image = Image.open(file_path)
except Exception as e:
messagebox.showerror("Error", f"Could not load image:\n{e}", parent=self)
return
self.update_processing()
def update_processing(self):
t = self.scale_var.get()
self.processed_image, self.processed_mask = self.process_with_scale(t)
self.update_preview()
def process_with_scale(self, t: float):
w, h = self.orig_image.size
factor_crop = 1024 / min(w, h)
factor_outfill = 1024 / max(w, h)
lower_bound = (0.5 * factor_outfill) if self.allow_shrink_var.get() else factor_outfill
factor = lower_bound + t * (factor_crop - lower_bound)
new_w = int(round(w * factor))
new_h = int(round(h * factor))
resized = self.orig_image.resize((new_w, new_h), Image.LANCZOS)
canvas_img = Image.new("RGBA", (1024, 1024), (0,0,0,0))
mask_img = Image.new("L", (1024,1024), 0)
paste_x = (1024 - new_w) // 2
paste_y = (1024 - new_h) // 2
dest_left = max(paste_x, 0)
dest_top = max(paste_y, 0)
dest_right = min(paste_x + new_w, 1024)
dest_bottom = min(paste_y + new_h, 1024)
dest_box = (dest_left, dest_top, dest_right, dest_bottom)
src_left = max(0, -paste_x)
src_top = max(0, -paste_y)
src_right = src_left + (dest_right - dest_left)
src_bottom = src_top + (dest_bottom - dest_top)
src_box = (src_left, src_top, src_right, src_bottom)
region = resized.crop(src_box)
canvas_img.paste(region, (dest_left, dest_top))
draw = ImageDraw.Draw(mask_img)
draw.rectangle(dest_box, fill=255)
final_img = canvas_img.convert("RGB")
return final_img, mask_img
def update_preview(self):
if self.processed_image is None:
return
preview = self.processed_image.copy().resize((512,512), Image.LANCZOS)
self.preview_photo = ImageTk.PhotoImage(preview)
self.preview_label.config(image=self.preview_photo)
def cancel(self):
self.destroy()
def ok(self):
if self.processed_image is None or self.processed_mask is None:
messagebox.showerror("Error", "Image processing failed.", parent=self)
return
outfill_flag = (self.scale_var.get() < 1.0)
self.parent.set_loaded_image(self.processed_image, self.processed_mask, outfill_flag)
self.destroy()
# =============================================================================
# Main Application Class
# =============================================================================
class DalleEditorApp(tk.Tk):
def __init__(self):
super().__init__()
self.title("DALL-E Editor")
self.geometry("1524x1030")
self.resizable(True, False)
self.option_add("*padx", 0)
self.api = DalleAPI()
self.loop = asyncio.new_event_loop()
self.loop_thread = threading.Thread(target=self.start_loop, args=(self.loop,), daemon=True)
self.loop_thread.start()
# Main left control panel
self.control_frame = tk.Frame(self, width=500, padx=1, pady=1)
self.control_frame.pack(side=tk.LEFT, fill=tk.Y, padx=1, pady=1)
# Top: Load Image button
self.load_image_button = tk.Button(self.control_frame, text="Load Image", width=20, command=self.open_load_image_dialog)
self.load_image_button.pack(pady=5)
# Generation Group
gen_frame = tk.Frame(self.control_frame)
gen_frame.pack(fill=tk.X, pady=5)
tk.Label(gen_frame, text="DALL-E Prompt:").pack(anchor="w")
self.dalle_prompt_text = tk.Text(gen_frame, height=20, width=60)
self.dalle_prompt_text.pack()
send_frame = tk.Frame(gen_frame)
send_frame.pack(pady=5)
self.send_dalle2_button = tk.Button(send_frame, text="Send to DALL-E 2", width=20, command=self.send_dalle2_image)
self.send_dalle2_button.grid(row=0, column=0, padx=5)
self.send_dalle3_button = tk.Button(send_frame, text="Send to DALL-E 3", width=20, command=self.send_dalle3_image)
self.send_dalle3_button.grid(row=0, column=1, padx=5)
self.hd_var = tk.BooleanVar(value=False)
self.hd_checkbox = tk.Checkbutton(gen_frame, text="DALL-E 3 HD", variable=self.hd_var)
self.hd_checkbox.pack(pady=(0,15))
# Editing Group
edit_group = tk.Frame(self.control_frame, relief="groove", borderwidth=1)
edit_group.pack(fill=tk.X, pady=5)
tk.Label(edit_group, text="Mask Drawing Options:").pack(anchor="w")
brush_frame = tk.Frame(edit_group)
brush_frame.pack(anchor="w", pady=2)
self.brush_option = tk.StringVar(value="off")
rb_off = tk.Radiobutton(brush_frame, text="Off", variable=self.brush_option, value="off", command=self.remove_brush_cursor)
rb_off.pack(side=tk.LEFT, padx=5)
rb_s = tk.Radiobutton(brush_frame, text="S", variable=self.brush_option, value="S")
rb_s.pack(side=tk.LEFT, padx=5)
rb_m = tk.Radiobutton(brush_frame, text="M", variable=self.brush_option, value="M")
rb_m.pack(side=tk.LEFT, padx=5)
rb_l = tk.Radiobutton(brush_frame, text="L", variable=self.brush_option, value="L")
rb_l.pack(side=tk.LEFT, padx=5)
self.reset_button = tk.Button(edit_group, text="Reset Mask", width=20, command=self.reset_mask)
self.reset_button.pack(pady=5, anchor="w")
tk.Label(edit_group, text="Image Edits Prompt:").pack(anchor="w")
self.editing_prompt_text = tk.Text(edit_group, height=20, width=60)
self.editing_prompt_text.pack(pady=5)
self.create_edit_button = tk.Button(edit_group, text="Edit/Fill with DALL-E 2", width=30, command=self.create_edit)
self.create_edit_button.pack(pady=5)
# Save button at bottom
self.save_button = tk.Button(self.control_frame, text="Save to Disk", width=20, command=self.save_to_disk)
self.save_button.pack(pady=15)
self.base_image = None
self.mask_image = None
self.original_loaded_mask = None
self.tk_image = None
self.canvas_image_id = None
self.loaded_outfill = False
self.mask_modified = False
self.last_draw_pos = None
self.brush_cursor_id = None
self.image_frame = tk.Frame(self, width=1024, height=1024, bd=0)
self.image_frame.pack(side=tk.RIGHT, padx=1, pady=1)
self.canvas = tk.Canvas(self.image_frame, width=1024, height=1024, bg="gray")
self.canvas.pack()
# Bind drawing events
self.canvas.bind("<ButtonPress-1>", self.on_mouse_down)
self.canvas.bind("<B1-Motion>", self.on_mouse_drag)
self.canvas.bind("<ButtonRelease-1>", self.on_mouse_release)
self.canvas.bind("<Motion>", self.on_mouse_move)
self.protocol("WM_DELETE_WINDOW", self.on_closing)
def start_loop(self, loop: asyncio.AbstractEventLoop):
asyncio.set_event_loop(loop)
loop.run_forever()
def on_closing(self):
if messagebox.askokcancel("Quit", "Do you want to quit?"):
self.loop.call_soon_threadsafe(self.loop.stop)
self.destroy()
def disable_controls(self):
self.load_image_button.config(state="disabled")
self.reset_button.config(state="disabled")
self.send_dalle2_button.config(state="disabled")
self.send_dalle3_button.config(state="disabled")
self.create_edit_button.config(state="disabled")
self.save_button.config(state="disabled")
self.dalle_prompt_text.config(state="disabled")
self.editing_prompt_text.config(state="disabled")
def enable_controls(self):
self.load_image_button.config(state="normal")
self.reset_button.config(state="normal")
self.send_dalle2_button.config(state="normal")
self.send_dalle3_button.config(state="normal")
self.create_edit_button.config(state="normal")
self.save_button.config(state="normal")
self.dalle_prompt_text.config(state="normal")
self.editing_prompt_text.config(state="normal")
def start_progress_indicator(self):
self.canvas.delete("all")
self.canvas_image_id = None
self.progress_start_time = time.time()
self._update_progress_indicator()
def _update_progress_indicator(self):
elapsed = time.time() - self.progress_start_time
factor = (math.sin(2 * math.pi * elapsed / 4.0) + 1) / 2
intensity = int(180 + (255 - 180) * factor)
color = f"#{intensity:02x}{intensity:02x}{intensity:02x}"
self.canvas.configure(bg=color)
self.progress_after_id = self.after(50, self._update_progress_indicator)
def stop_progress_indicator(self):
if hasattr(self, 'progress_after_id') and self.progress_after_id is not None:
self.after_cancel(self.progress_after_id)
self.progress_after_id = None
self.canvas.configure(bg="gray")
def on_api_error(self, error, prev_image, prev_mask):
self.stop_progress_indicator()
self.enable_controls()
self.base_image = prev_image
self.mask_image = prev_mask
self.update_display()
messagebox.showerror("API Error", f"An error occurred:\n{error}")
def reset_mask(self):
if self.base_image is None:
messagebox.showerror("Error", "No image loaded.")
return
if self.original_loaded_mask is not None:
self.mask_image = self.original_loaded_mask.copy()
else:
self.mask_image = Image.new("L", self.base_image.size, 255)
self.mask_modified = False
self.update_display()
def send_dalle2_image(self):
prompt = self.dalle_prompt_text.get("1.0", tk.END).strip()
if not prompt:
messagebox.showerror("Error", "Please enter a prompt for image creation.")
return
prev_image = self.base_image
prev_mask = self.mask_image
self.disable_controls()
self.start_progress_indicator()
async def async_generate():
try:
new_image = await self.api.generate_image(prompt, model="dall-e-2", timeout=40)
self.after(0, self.on_new_image_generated, new_image)
except Exception as e:
self.after(0, self.on_api_error, e, prev_image, prev_mask)
asyncio.run_coroutine_threadsafe(async_generate(), self.loop)
def send_dalle3_image(self):
prompt = self.dalle_prompt_text.get("1.0", tk.END).strip()
if not prompt:
messagebox.showerror("Error", "Please enter a prompt for image creation.")
return
prev_image = self.base_image
prev_mask = self.mask_image
self.disable_controls()
self.start_progress_indicator()
params = {}
if self.hd_var.get():
params["quality"] = "hd"
async def async_generate():
try:
new_image = await self.api.generate_image(prompt, model="dall-e-3", **params, timeout=40)
self.after(0, self.on_new_image_generated, new_image)
except Exception as e:
self.after(0, self.on_api_error, e, prev_image, prev_mask)
asyncio.run_coroutine_threadsafe(async_generate(), self.loop)
def on_new_image_generated(self, new_image: Image.Image):
self.stop_progress_indicator()
self.enable_controls()
if not new_image or not hasattr(new_image, "size"):
self.on_api_error("Received invalid image from API", self.base_image, self.mask_image)
return
if new_image.size != (1024,1024):
messagebox.showwarning("Warning", f"Image resolution {new_image.size} does not match 1024x1024.")
self.base_image = new_image
self.mask_image = Image.new("L", self.base_image.size, 255)
self.original_loaded_mask = None
self.mask_modified = False
self.loaded_outfill = False
self.update_display()
def create_edit(self):
if self.base_image is None:
messagebox.showerror("Error", "No image loaded.")
return
if (not self.mask_modified) and (not self.loaded_outfill):
messagebox.showerror("Error", "No mask drawn or loaded. Use the mask drawing options to mark areas for editing.")
return
prompt = self.editing_prompt_text.get("1.0", tk.END).strip()
if not prompt and self.loaded_outfill:
prompt = "The image is filled edge-to-edge with content"
self.editing_prompt_text.delete("1.0", tk.END)
self.editing_prompt_text.insert("1.0", prompt)
prev_image = self.base_image
prev_mask = self.mask_image
self.disable_controls()
self.start_progress_indicator()
base_copy = self.base_image.copy()
mask_copy = self.mask_image.copy()
async def async_edit():
try:
edited_image = await self.api.edit_image(base_copy, mask_copy, prompt)
self.after(0, self.on_edit_image_generated, edited_image)
except Exception as e:
self.after(0, self.on_api_error, e, prev_image, prev_mask)
asyncio.run_coroutine_threadsafe(async_edit(), self.loop)
def on_edit_image_generated(self, edited_image: Image.Image):
self.stop_progress_indicator()
self.enable_controls()
if not edited_image or not hasattr(edited_image, "size"):
self.on_api_error("Received invalid edited image from API", self.base_image, self.mask_image)
return
if edited_image.size != (1024,1024):
messagebox.showwarning("Warning", f"Image resolution {edited_image.size} does not match 1024x1024.")
self.base_image = edited_image
self.mask_image = Image.new("L", self.base_image.size, 255)
self.original_loaded_mask = None
self.mask_modified = False
self.loaded_outfill = False
self.update_display()
def save_to_disk(self):
if self.base_image is None:
messagebox.showerror("Error", "No image to save.")
return
file_path = filedialog.asksaveasfilename(defaultextension=".png", filetypes=[("PNG Files", "*.png")])
if file_path:
try:
self.base_image.save(file_path, "PNG")
except Exception as e:
messagebox.showerror("Error", f"Error saving image:\n{e}")
def open_load_image_dialog(self):
file_path = filedialog.askopenfilename(
title="Select Image",
filetypes=[("Image Files", "*.png;*.jpg;*.jpeg;*.bmp;*.gif"), ("All Files", "*.*")]
)
if file_path:
try:
img = Image.open(file_path)
except Exception as e:
messagebox.showerror("Error", f"Could not load image:\n{e}")
return
w, h = img.size
if w == h:
base_img = img.resize((1024,1024), Image.LANCZOS).convert("RGB")
mask = Image.new("L", (1024,1024), 255)
self.set_loaded_image(base_img, mask, loaded_outfill=False)
else:
ImageLoadDialog(self, file_path)
def set_loaded_image(self, image: Image.Image, mask: Image.Image, loaded_outfill: bool):
self.base_image = image
self.mask_image = mask.copy()
self.original_loaded_mask = mask.copy() # Save original loaded mask.
self.mask_modified = False
self.loaded_outfill = loaded_outfill
self.update_display()
def on_mouse_down(self, event):
if self.base_image is not None and self.brush_option.get() != "off":
self.last_draw_pos = (event.x, event.y)
self.draw_mask_segment(event.x, event.y, event.x, event.y)
self.update_display()
def on_mouse_drag(self, event):
if self.base_image is not None and self.brush_option.get() != "off" and self.last_draw_pos is not None:
x0, y0 = self.last_draw_pos
self.draw_mask_segment(x0, y0, event.x, event.y)
self.last_draw_pos = (event.x, event.y)
self.update_display()
def on_mouse_release(self, event):
self.last_draw_pos = None
def on_mouse_move(self, event):
if self.base_image is None or self.brush_option.get() == "off":
self.canvas.delete("brush_cursor")
return
if self.brush_option.get() == "S":
brush_diameter = 15
elif self.brush_option.get() == "M":
brush_diameter = 40
elif self.brush_option.get() == "L":
brush_diameter = 60
else:
brush_diameter = 15
r = brush_diameter / 2
x, y = event.x, event.y
self.canvas.delete("brush_cursor")
self.brush_cursor_id = self.canvas.create_oval(x - r, y - r, x + r, y + r,
outline="black", dash=(2,2), width=2, tags="brush_cursor")
self.canvas.tag_raise("brush_cursor")
def remove_brush_cursor(self):
self.canvas.delete("brush_cursor")
self.brush_cursor_id = None
def draw_mask_segment(self, x0, y0, x1, y1):
option = self.brush_option.get()
if option == "off":
return
if option == "S":
brush_diameter = 20
elif option == "M":
brush_diameter = 40
elif option == "L":
brush_diameter = 60
else:
brush_diameter = 20
radius = brush_diameter / 2
draw = ImageDraw.Draw(self.mask_image)
dx = x1 - x0
dy = y1 - y0
dist = math.sqrt(dx*dx + dy*dy)
if dist < 1:
draw.ellipse([x1 - radius, y1 - radius, x1 + radius, y1 + radius], fill=0)
else:
px = -dy/dist * radius
py = dx/dist * radius
points = [(x0 + px, y0 + py),
(x0 - px, y0 - py),
(x1 - px, y1 - py),
(x1 + px, y1 + py)]
draw.polygon(points, fill=0)
draw.ellipse([x0 - radius, y0 - radius, x0 + radius, y0 + radius], fill=0)
draw.ellipse([x1 - radius, y1 - radius, x1 + radius, y1 + radius], fill=0)
def update_display(self):
if self.base_image is None:
return
base_disp = self.base_image.convert("RGBA")
overlay = Image.new("RGBA", self.base_image.size, (0,0,0,0))
binary_mask = self.mask_image.point(lambda p: 255 if p == 0 else 0)
overlay.paste((255,0,0,128), (0,0), binary_mask)
display_img = Image.alpha_composite(base_disp, overlay)
self.tk_image = ImageTk.PhotoImage(display_img)
if self.canvas_image_id is None:
self.canvas_image_id = self.canvas.create_image(0,0, anchor="nw", image=self.tk_image)
else:
try:
self.canvas.itemconfig(self.canvas_image_id, image=self.tk_image)
except tk.TclError:
self.canvas_image_id = self.canvas.create_image(0,0, anchor="nw", image=self.tk_image)
self.canvas.tag_raise("brush_cursor")
def main():
app = DalleEditorApp()
app.mainloop()
if __name__ == "__main__":
main()
Reusable Components and Methods:
DalleAPI Class:
- Fully reusable asynchronous wrapper methods (
generate_image and edit_image) for invoking DALL-E API endpoints efficiently.
- Robust handling of base64-encoded API responses, providing ready-to-use PIL Image objects.
ImageLoadDialog Class:
- Customizable image loading dialog with scaling and cropping controls, ideal for incorporation into other Tkinter-based applications needing advanced image input options.
- Interactive Mask Drawing Logic:
- Smooth, continuous stroke logic implemented through PIL’s ImageDraw library, ensuring masks are accurately represented for editing.
- API Integration Patterns:
- Asynchronous threading via Python’s
asyncio and thread-based event loops, allowing responsive UIs during API calls—ready-to-use examples for other applications consuming asynchronous APIs.
The provided code is cleanly structured, Pythonic, and purpose-built for direct integration or adaptation into other Python projects targeting similar API-based workflows.
Explore, integrate, and extend freely—DALL-E Editor is designed for developers to adapt, improve, and seamlessly integrate advanced image-generation capabilities directly into their Python applications.