Hello, we are trying to make a multi-class classification model which classifies company review in Jobplanet, which is basically a Korean glassdoor. I saw some recent research where people use GPT to annotate labels to reduce cost and time.
So we have done human annotation for 660 company reviews. And the labels are follow:
“1. growth potential and vision: long-term growth potential of the company, business expansion, competitiveness in the industry, vision, future direction of the company, personal growth potential and \n”
“2. Benefits and salary: salary levels, bonuses, salary increases, welfare benefits, health insurance, annual leave, and in-house training offered to employees \n”
“3. Work environment and WLB: working environment, work-life balance, work intensity, working hours, possibility to work from home, breaks, office facilities, location of workplace, mobility between organizations, fatigue \n”
“4. Company culture: company atmosphere, office politics (lines), working style, relationships between employees, communication style, collaboration style, free annual leave, horizontal, vertical, reporting paperwork, retention (L-Mun) - system \n”
“5. Management (Leadership): Compensation/performance evaluation, Personnel policy, Decision-making style, Management strategy, Consideration for employees, Recruitment of new employees, Hierarchy/system, Lack of promotion Appropriate timing: Because management should organize the organization at the right time, Employment retention (Elmuwon)-Systems\n”
“6. Other: Text not applicable to above\n\n”
I have followed OpenAI finetuning API and made a train/val/test set 300/100/260. And made a JSONL file following the format of System, user, assistance. Below results are the system message of the model.
Below results shows the training&validation results of fine-tuning gpt-4o-mini.
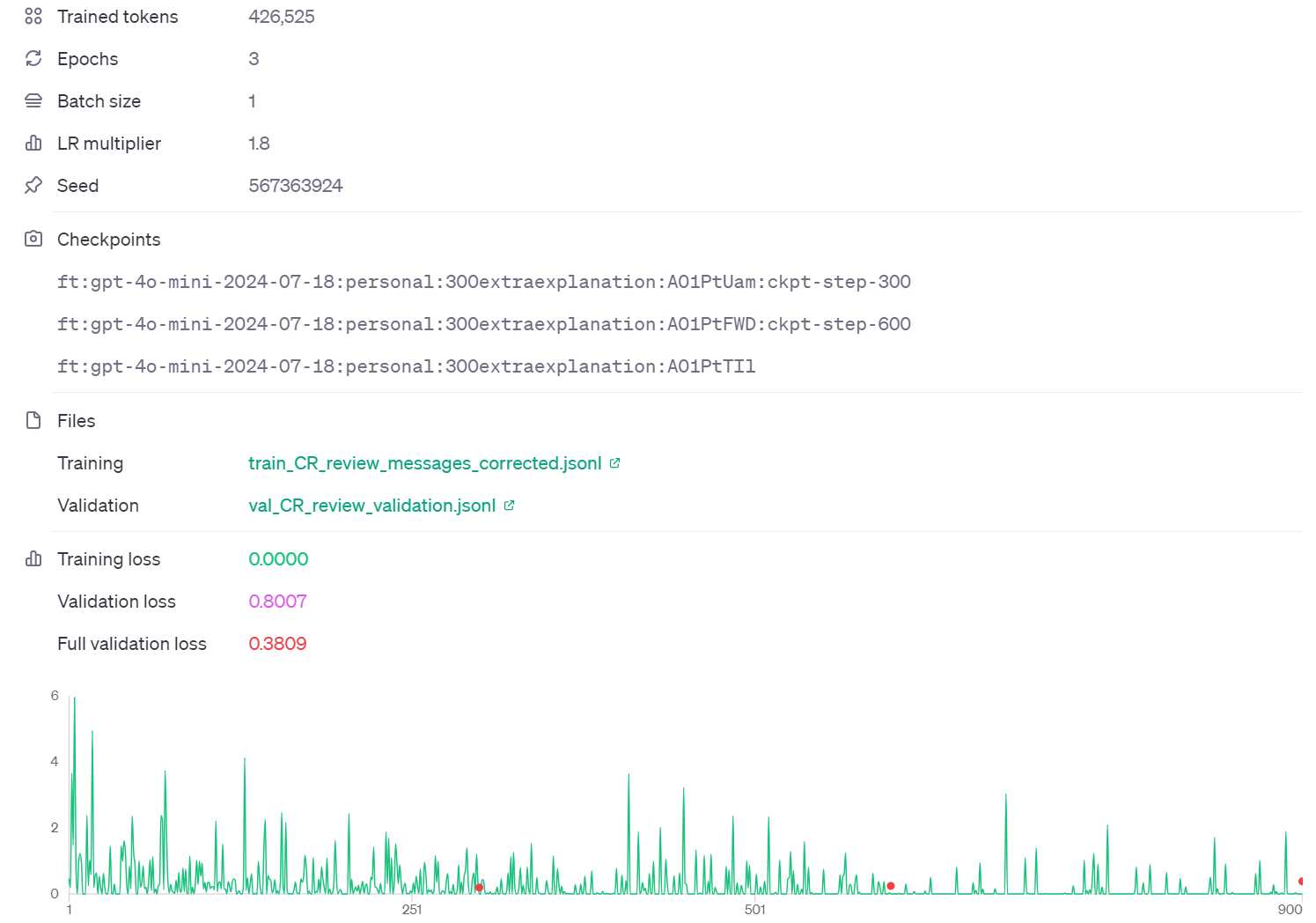
The results in training and validation seems alright but when we test on test_dataset the results are really bad as follow:
accuracy 0.08 260
macro avg 0.06 0.06 0.05 260
weighted avg 0.09 0.08 0.08 260
[eval of fine-tune model]
accuracy 0.02 260
macro avg 0.00 0.00 0.00 260
weighted avg 0.05 0.02 0.02 260
[eval of baseline:GPT-4o mini]
The good thing is that fine-tune model was better than baseline model(GPT-4o mini). However, we are expecting the fine-tune model to be at least 0.7 accuracy to use it as annotator.
We try to analyze the problems and the followings are what we came up of:
(main)The multi-class classification is challenging&vague, some classes overlap and when doing human-annotation the standard were also vague. Human annotation should be re-established.
(main) we have only tried GPT4o-mini and could try GPT3.5, GPT4o etc… and hyperparameters
(sub) When fine-tuning the text has both English and Korean which makes the model to understand and learn
So, our main questions are
- Should we do humman annotation again?
- Is it better to make system message more simple?
- Should we try fine-tuning GPT3.5-turbo, GPT-4o instead, maybe change hyperparameter(learning late, epoch, etc…)
- Is it better to use single language on system, user, assistance?
- Any tips or comments would be appreciated!
Thank You for your help!
