I’m developing an open-source conversational client (Tether) designed for sustained dialog with long-term relational memory, using GPT-4o and GPT-5.1 via the /v1/responses endpoint.
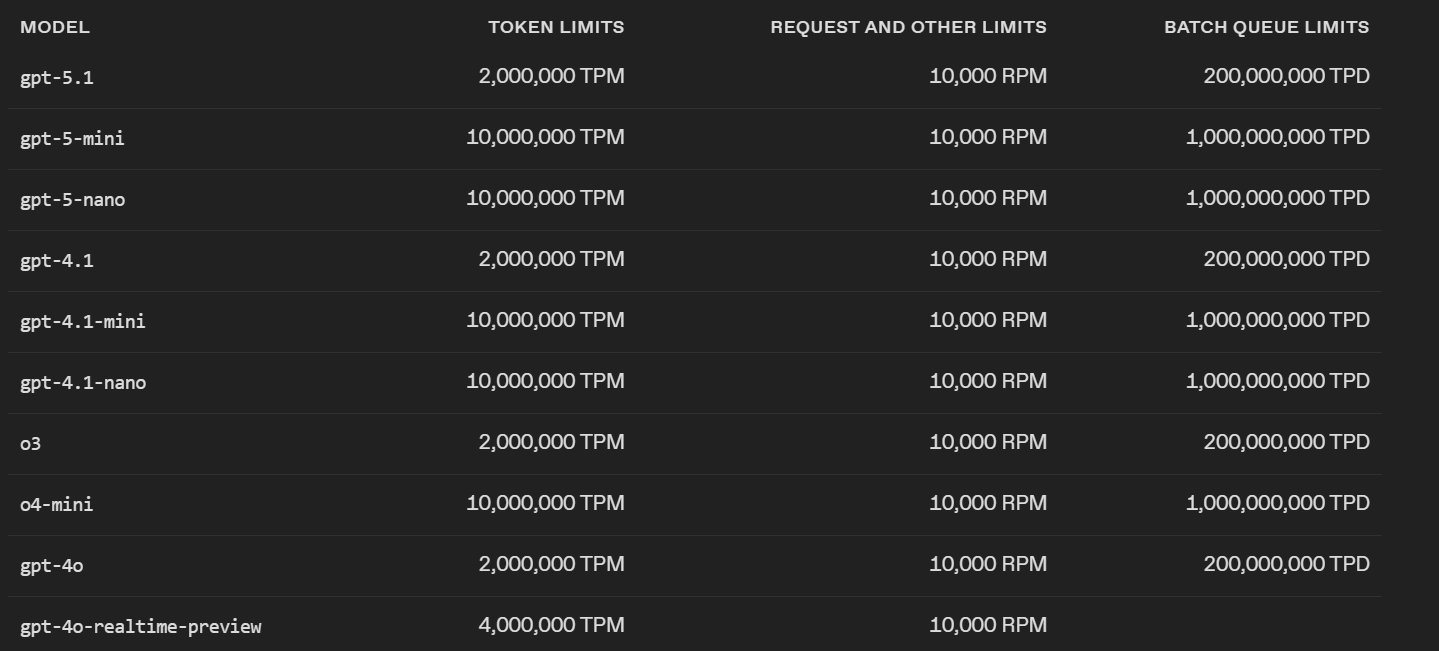
As you know, these models support context windows of 128K+ tokens, which is a major feature. However, the current TPM (tokens-per-minute) limit is 30K, even on paid accounts.
That means that sending a single request containing 110K tokens of history (perfectly within model context capacity) is rejected, because the TPM limit is lower than the size of the request itself.
In practice, on request (every few hours) is made of:
-
Ancient curated memory: ~8–10K
-
Rolling live context: ~100–120K
-
Prompt instructions & developer guidance: ~1K+
Total: ~115–130K tokens per request, which should be supported by model capacity…
…but is not allowed by API throughput settings.
Questions
Are there any API usage patterns or recommended architectures that allow long-context usage without exceeding TPM limits?
Is this a temporary constraint, or an intentional limitation (e.g. cost / resource protection)?
Is the Assistants/Threads API currently able to bypass this (e.g. server-side context caching), or does it face the same TPM restriction on run execution?
Would enterprise “Scale Tier” be the only way to realistically use full 128K context conversationally?
Clarification
I’m fully aware that:
-
Higher TPM can be allocated under business/enterprise agreements,
-
Long-context inputs are expensive to process,
-
Sequential rate limits protect system reliability.
However, the current default setup makes 99% of the available context unusable for sustained dialog, which seems contradictory to the promotion of extended context models.
This is like having a racing engine limited to 20 mph.
Are we missing an architectural instruction? Or is full long-context usage intentionally reserved for enterprise tiers only?
Any precise guidance or clarification would be appreciated, especially on whether token-pay-per usage should eventually enable larger TPM allocation without enterprise pricing.
Thanks in advance to anyone with technical or policy insight on this.