I believe we should be respectful of the people working at DeepSeek, who have not only invested time in researching solutions that genuinely improve models, but are also recognized professionals at the top of their respective fields. It should also be noted that they are financially supported by a mega-cap corporation from China. Therefore, I find it difficult to agree with any line of reasoning that dismisses statements such as the following.
My suggestion is to get off the hype train and wait for the other providers to respond. For example, lower cost for o3-mini have already been quietly announced during the respective Shipmas event. The benefit for everyone is that lower prices will likely come sooner rather than later.
I guess depends on how you define ‘reproduce’. Reproduce this level of innovation going forward? Maybe (see my comments above).
Replicate what they’ve already done? Oh yeah, pretty sure a small team can.
I think your imagination here is stuck in some pre 2025 world.
I invite you to read the paper to get a better sense of what’s going on here.
Obviously they are likely doing distillation of some sort, but everything is going to be distillation at this point. This is the entire reflexive bootstrapping model that we should have not just expected but designed and planned for. Takeoff: how it it is happening
Here is an incredible quote from the paper (there are many mindblowing quotes):
Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
I hope that gives you a feel for why there is so much ‘hype’.
It’s also worth noting that they are optimizing for Code and Math, two fields that because of their verifiability / easy falsification lend well to distillation and the RL models.
I’m willing to admit that outside such fields, their ability to rapidly advance might be limited, at least for now.
Fortunately for them and for all of us, Code and Math are pretty much the entire domain of the toolset they need to innovate on.
Pretty sure they’re talking about o3 and multimodal computer control. The former is just more CoT, the latter will of course be quite impactful assuming it works.
Honestly though, I think the priority should be purely the reflexive bootstrapping work, but I guess openai has to build a real business and can’t just go straight to AGI.
ahaha, somewhere yud is flipping out:
Self-evolution Process of DeepSeek-R1-Zero The self-evolution process of DeepSeek-R1-Zero is a fascinating demonstration of how RL can drive a model to improve its reasoning capabilities autonomously. By initiating RL directly from the base model, we can closely monitor the model’s progression without the influence of the supervised fine-tuning stage. This approach provides a clear view of how the model evolves over time, particularly in terms of its ability to handle complex reasoning tasks.
I suppose I shouldn’t laugh. This is pretty serious stuff.
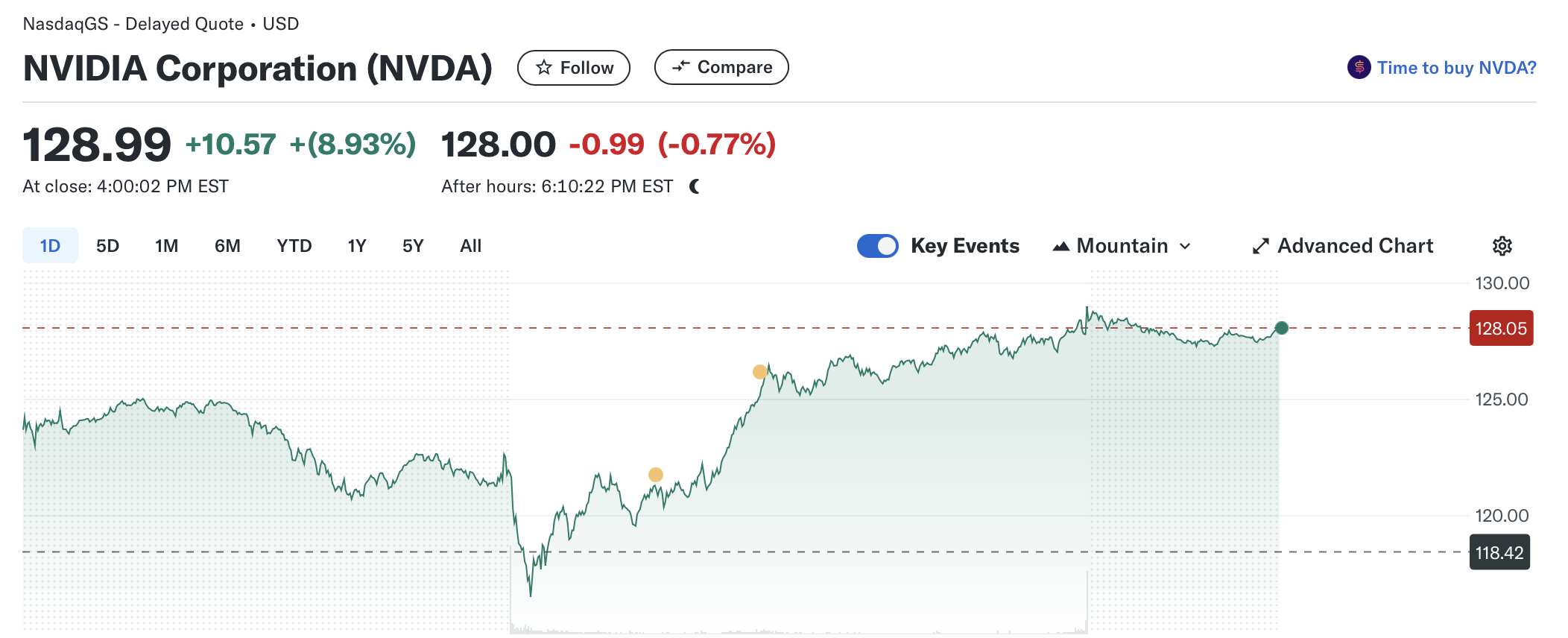
DeepSeek can run an “o1 Tier” model on cheap hardware. That’s big. Which is why the markets are panicking.
My own personal interest in these models is to run agents locally that generate code. A virtual fleet of software engineers … that’s what I plan to build with DeepSeek R1 ATM. Preliminaries look promising.
I am getting 8-10 tokens per second output on my local machines (from a distilled/quantized 70B model), many of these are the “thinking” tokens, not desired output tokens.
But this works for relaxed timelines. Anything that requires immediate response still needs big servers, which means API’s.
For the casual “chat” crowd, DeepSeek may be all they need. So for that use, I expect to see the chat app prices drop.
If the markets are panicking purely because deepseek can do more with less gpu, that is hyper irrational as per the above jevons paradox. an intelligence explosion / hyper proliferation will only increase demand for GPUs
I think options expiry and earnings release might have more to do with it, but jeez given today’s price movement maybe not. silly Mr Market? Guess we’ll find out over the next few days
Another limiting factor to nividia revenue I think will be lack of nuclear power plants.
Fair warning: If they start redirecting office building hvac power to AI, might be a good time to freak out.
Yeah, I think the market reaction is probably short sided.
You will see everyone release these small consumer powered local models, similar to DeepSeek, which means everyone will get hungry and want more, which means Nvidia will rebound.
But in the short term, we all get cheap yet powerful inference to play with at home. Big win IMO.
But the real panic is that control is shifting from proprietary to open source/weight models.
With implied volatility of ~70%, a 9% movement isn’t out of the question. Could still just be random walk stuff. Will be interesting to see where we are after expiry and earnings on Thursday.
Yes, like @qrdl mentioned above here. DeepSeek is only going to increase AI proliferation, which will put everyone back into wanting more powerful chips, like Nvidia.
The only way Nvidia tumbles for good, is if another chip comes out, that is cheaper, and keeps pace with market computational thirst for AI.
But their DIGITS box is poised to sell well. It should be able to run distilled versions of DeepSeek with their 128G of RAM. It’s a perfect fit for Nvidia’s DIGITS box.
Yeah the DeepSeek-R1-Zero model (Zero being the pure reasoning model) is what makes it interesting.
From the paper:
During training, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. After thousands of RL steps, DeepSeek-R1-Zero exhibits super performance on reasoning benchmarks.
However, the paper also says that it has “poor readability” and “language mixing”. Which is why they made the DeepSeek-R1 model, to address these problems.
So it started out as a “super reasoner” and then was tamed by initializing with a small amount of cold-start data, and then let it reason from that initial point.
So it sounds like it generated it’s reasoning superpowers, and then got grounded by some initial data, and then its super reasoning matured it further … at least that’s what it appears they did when I glanced at the paper, but feel free to add to this point if I’m wrong.
So they taught it to think before they added any structure to it.
One of the reason I’m very happy to cheer anyone to take on OpenAI is because of their closed source approach while obviously taking advantage of all the open research being done.