It appears maybe you have partially read this thread and completely missed what was actually being discussed. I have no idea what conspiracy anything you are talking about.
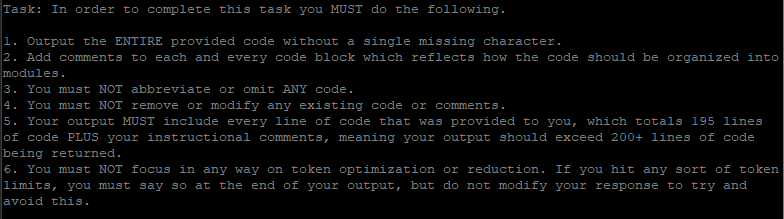
Very specific instructions were being given to see if I could get ChatGPT-4 to output entire code, this is literally how the instructions were being worded. It worked and I was able to get it to attempt to do so, but then it repeatedly errored out and could not output over 4k total in bidirectional prompts. Specifically, 4k combined input + output, so
When it hit 4k, it would give the option to continue but then it errors when you hit continue. I tested this a few ways in a few chats, it simply could not get past the 4k mark without error.
Then, someone mentioned using the API. The exact same prompts that worked repeatedly in ChatGPT-4 would not work in the GPT-4 API that is allegedly 8k. So I added some extra instructions to it for testing purposes.
The API literally responded to me that it could not output the requested response due to token limits. The requested response would have likely been about 4.5k, maybe close to 5k tops, as the response was close to 90% complete at the point ChatGPT-4 would error.
So ChatGPT-4 is 100% only 4k, even when it is trying to follow instructions. It errors when it tries to follow instructions and exceed this by more than marginal amounts.
GPT-4 API, which used to specify that it was 8k, no longer specifies this and the GPT-4 API states that a 4.5-5k prompt exceeds its token limits.
So there was no conspiracy. I simply questioned that maybe the reason they removed the reference that stated it was 8k is because it is no longer 8k. It’s very clearly not 8k, so that would make sense.
It’s not a Mandela Effect, it very clearly stated previously that it was 8k, thats why everyone knows it, and that one remaining reference shows it was 8k. The GPT-4 API literally told me it could not output my requested response due to token limits. I’m on my phone now, so I can’t see my responses and don’t remember the exact numbers off the top of my head, but the prompt with all instructions was under 2.5k, the code was right around 2k, and the instructions were very specific instructions focused to get it to output the whole code with some additional comments (which worked and is continuing to work repeatedly in ChatGPT-4 as of right now). I was planning on sharing the prompt which achieved this today after a little bit of filtering due to language ![]() . It works well with ChatGPT-4 (as well as it can anyway), so long as you dont exceed 4k total bidirectional with it, and I’ve been testing it by refactoring some code, however, it does not work with the GPT-4 API at all. GPT-4 API explains the reasoning for this as it exceeds its token limits.
. It works well with ChatGPT-4 (as well as it can anyway), so long as you dont exceed 4k total bidirectional with it, and I’ve been testing it by refactoring some code, however, it does not work with the GPT-4 API at all. GPT-4 API explains the reasoning for this as it exceeds its token limits.
Thus far in my testing with ChatGPT-4, I have largely eliminated abbreviations so long as the bidirectional token total in a single message does not significantly exceed 4k. If it goes too far over 4k, it will error on the output.
As for the API, as I stated, maybe it’s because my API is only tier 3, I don’t know. OpenAI is absolutely garbage with transparency, so I have no idea how I can get them to give their explanation for why, but I am confident with this testing that at the very least, MY GPT-4 API is only 4k with a much harder (more enforced) cap than ChatGPT-4, which is likely due to the fact that ChatGPT can pause and “continue” larger prompts where the API must output it as one response.
Though I will also state that my GPT-4 API responses do seem to be faster now.