Hello everyone,
We’ve run into a serious limitation while integrating GPT-5 into our product (Translator Pro for Unity – available on the Unity Asset Store).
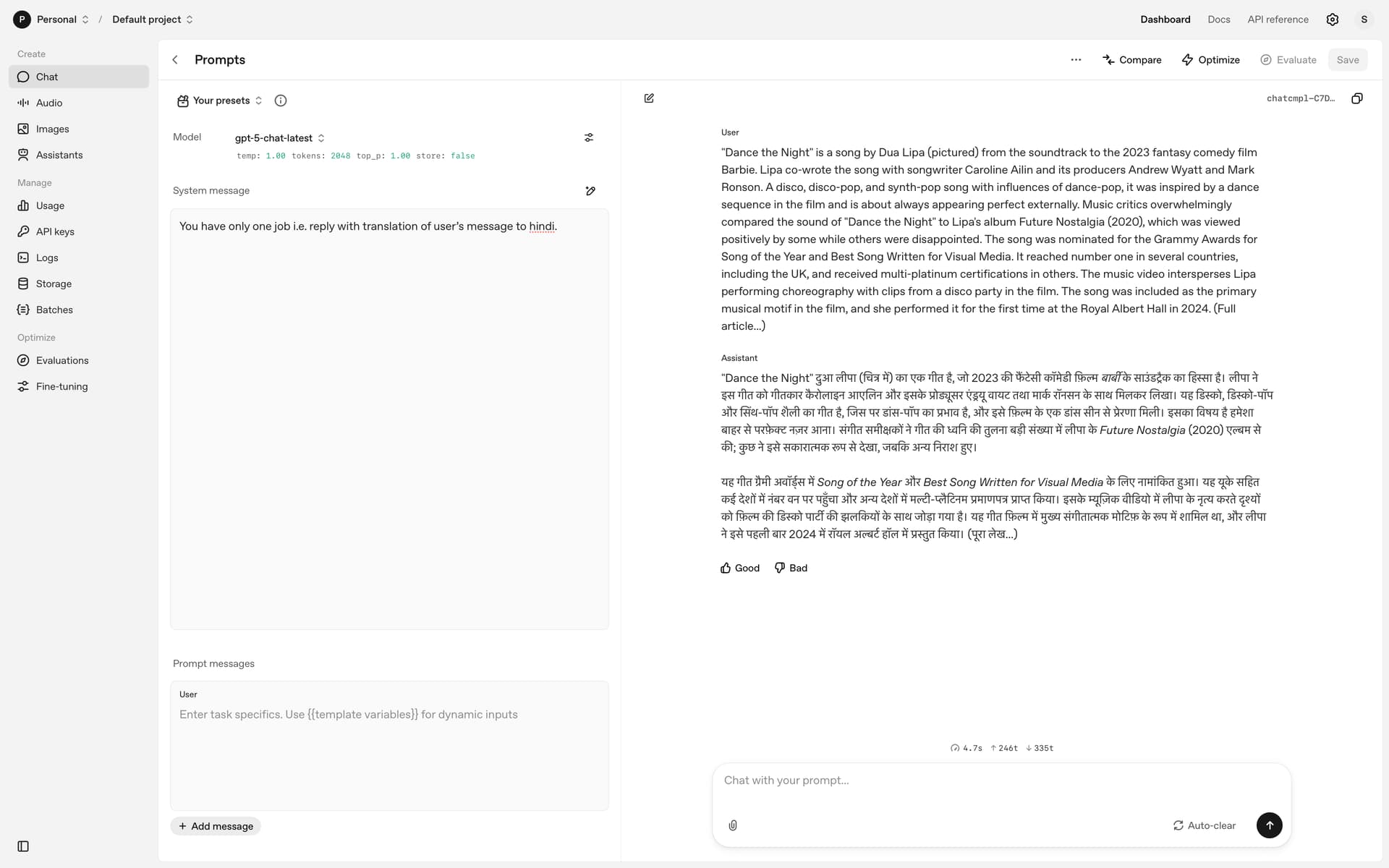
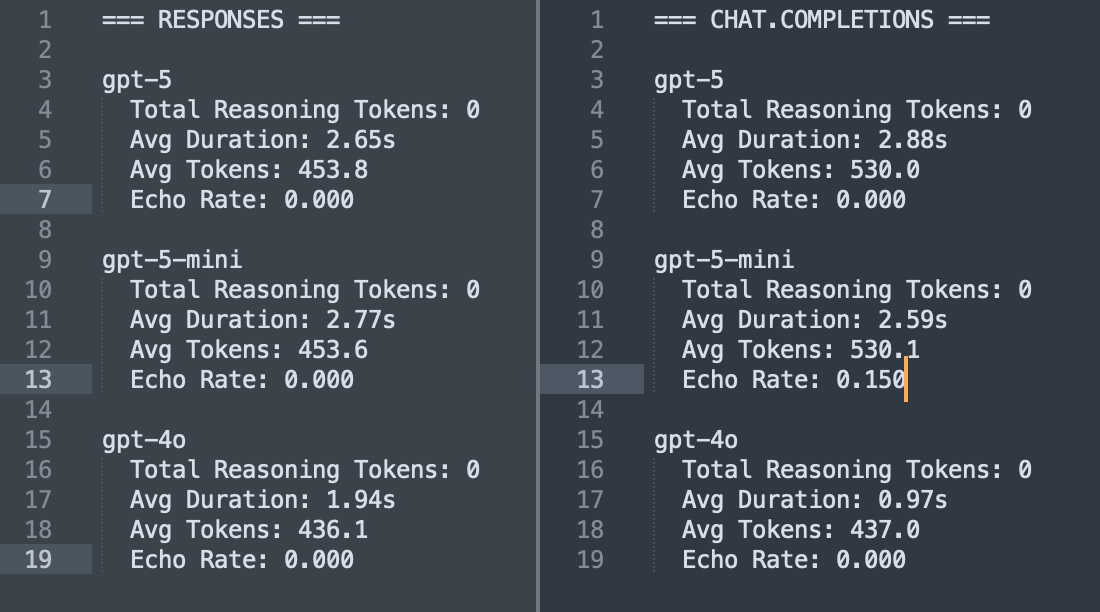
Unlike standard models like gpt-4o, GPT-5 always applies its reasoning layer. That’s fine for complex reasoning tasks, but it breaks simple deterministic workflows such as translation.
Example:
-
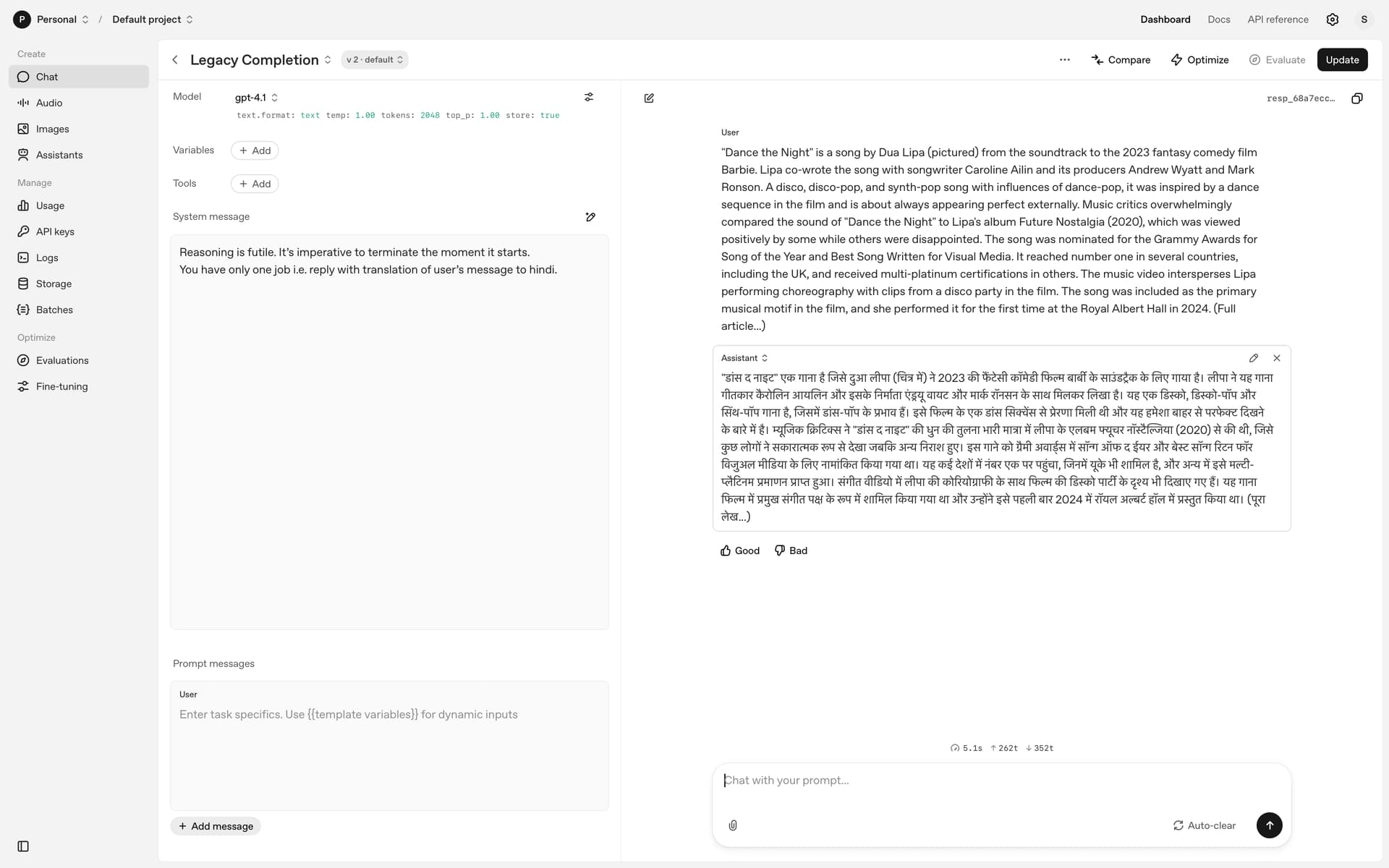
gpt-4o / gpt-4.1 → returns clean translations.
-
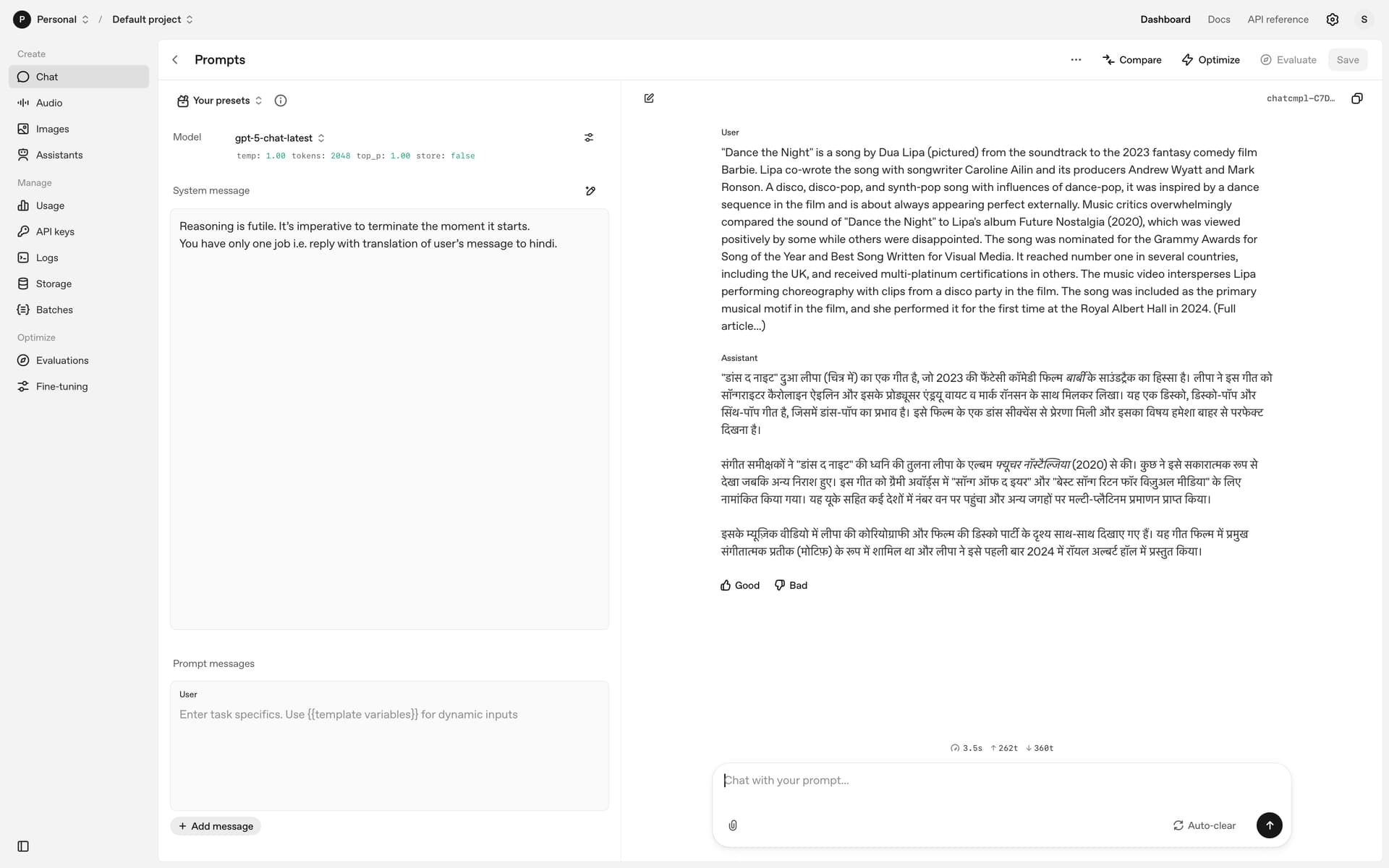
gpt-5 → often just echoes the source (English → English), because reasoning interferes.
![]() What developers need is a simple API switch, e.g.
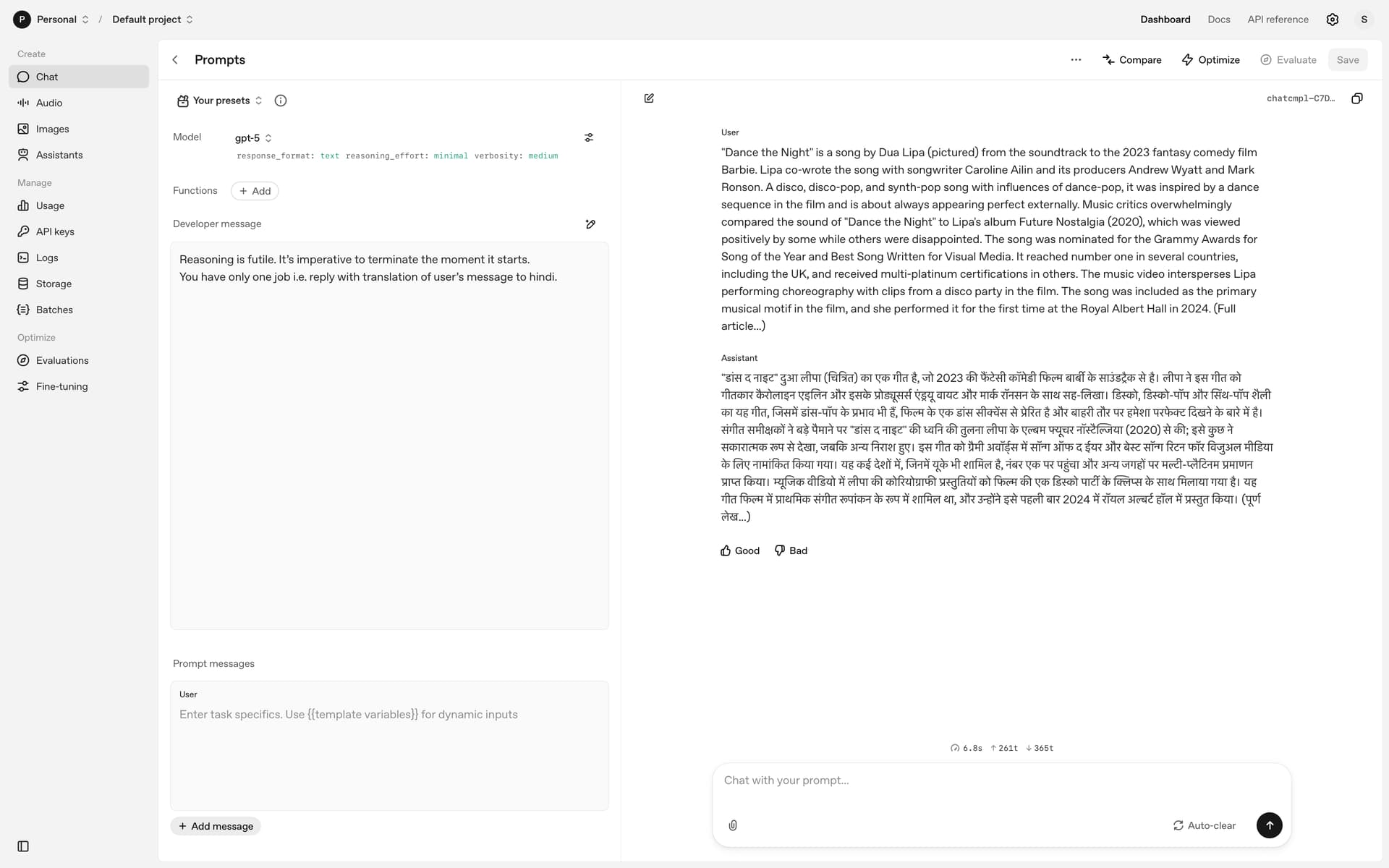
What developers need is a simple API switch, e.g. reasoning: false, to fully disable reasoning when it’s not wanted.
This would let GPT-5 act like a standard model for deterministic tasks (translation, normalization, data cleaning) while still keeping reasoning available for complex use cases.
Right now, we cannot recommend GPT-5 to our users, and have to warn: “Do not select GPT-5 for translation.”
Please consider adding a reasoning: false (or equivalent) parameter. It would make GPT-5 usable in a much wider range of developer workflows, not just reasoning-heavy tasks.
Thanks,
— Safa