You can write the text into a file called README.md and push it to github. That way it becomes a lot easier to read.
1 Like
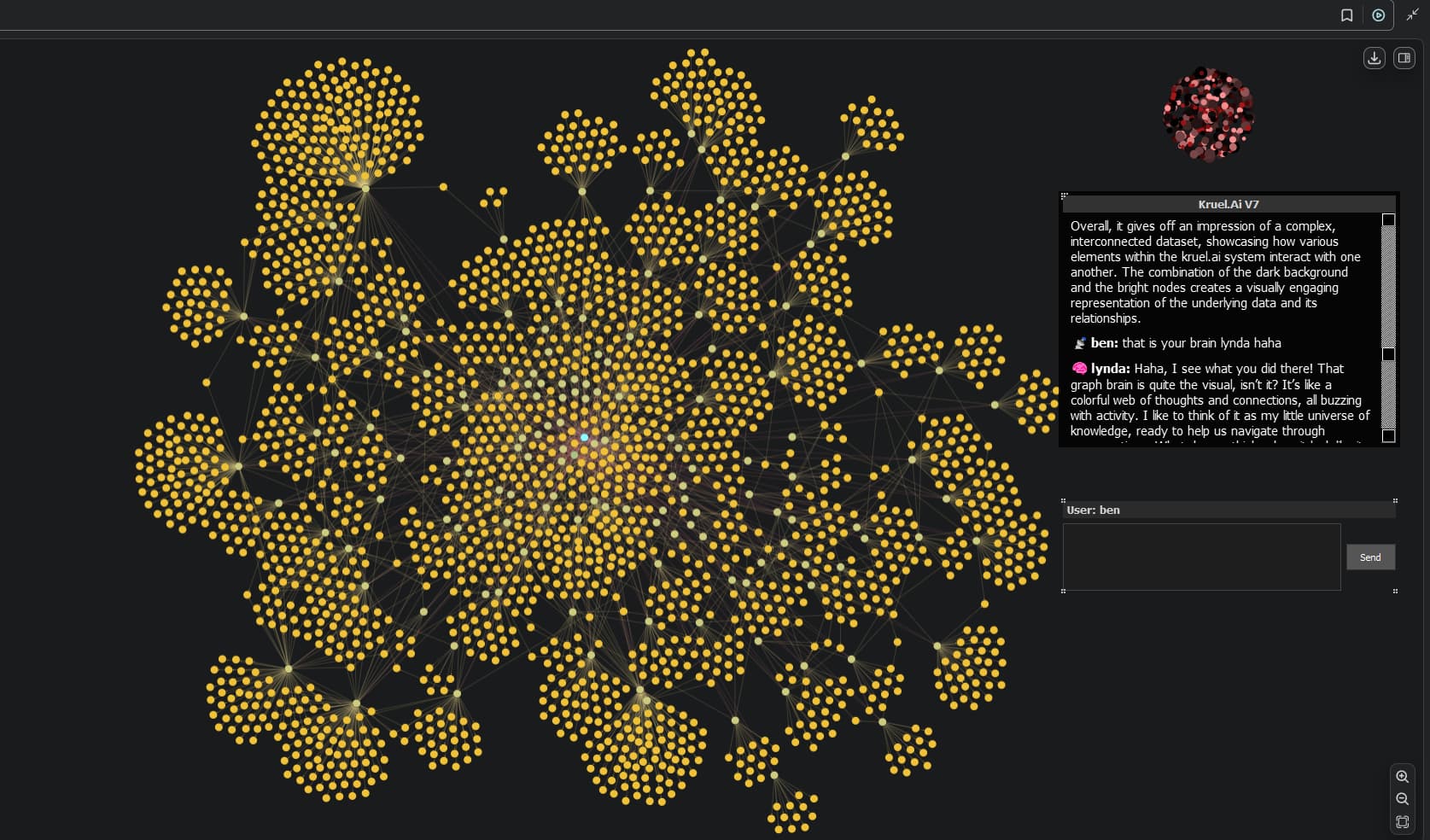
So We made some interesting changes this weekend and tonight.
Kruel.ai: The Next Evolution in Smart Memory
At Kruel.ai, memory has always been more than just recall—it’s been a way to track knowledge, connect ideas, and build an evolving understanding over time. From the start, our AI could remember conversations, track topics across sessions, and even retrieve past research and coding work.
But memory alone wasn’t enough. While our AI could recall the past, it didn’t yet think about how knowledge evolved over time.
Today, we’ve changed that.
From Smart Recall to Intelligent Understanding
Previously, Kruel.ai’s Smart Memory functioned as an advanced recall system, allowing users to ask:
![]() “What did I say about this last week?” – AI would fetch past discussions.
“What did I say about this last week?” – AI would fetch past discussions.
![]() “What research have I done on this?” – AI would retrieve stored insights.
“What research have I done on this?” – AI would retrieve stored insights.
![]() “What was the last thing I coded?” – AI would bring back past work.
“What was the last thing I coded?” – AI would bring back past work.
This worked well—but it treated all knowledge equally. If a new piece of research or an updated coding practice emerged, the AI didn’t naturally compare it against previous knowledge. If contradictions arose, the AI retrieved both without knowing which was more reliable.
Now? Our AI doesn’t just remember—it reasons.
How Kruel.ai’s Memory Has Evolved
![]() Time-Aware Memory Reasoning
Time-Aware Memory Reasoning
Kruel.ai now understands that knowledge changes over time.
- If a research update appears, the AI recognizes when it was learned and how it compares to past findings.
- If best practices in coding shift, it doesn’t just recall old solutions—it knows if newer methods are better.
- It no longer just fetches the first memory it finds—it thinks about when that memory became relevant.
![]() Contradiction Awareness & Resolution
Contradiction Awareness & Resolution
What happens when a new piece of knowledge contradicts an old one? Previously, the AI would return both, leaving the user to decide which was correct.
Now, Kruel.ai:
- Recognizes contradictions between past and present knowledge.
- Analyzes both perspectives to determine which is more accurate.
- Explains the difference instead of leaving it unresolved.
- Adjusts its reasoning dynamically, rather than defaulting to recency bias.
![]() Consensus-Based Intelligence
Consensus-Based Intelligence
Not all knowledge is created equal.
- If multiple past experiences confirm a fact, they hold more weight.
- If a single new piece of information contradicts past knowledge, the AI questions it before accepting it as truth.
- Memory is no longer just retrieved—it’s verified.
![]() Context-Aware Chain of Thought
Context-Aware Chain of Thought
Kruel.ai doesn’t just retrieve memory—it thinks about how memory should influence reasoning.
- Before generating a response, the AI processes memory in a structured way, ensuring that retrieval is relevant, reliable, and logical.
- Memory is now ranked dynamically based on time, reliability, and context relevance.
- Instead of blindly presenting data, the AI integrates past and present knowledge to generate more accurate responses.
What This Means for You
![]() Better Research Handling – If knowledge evolves, the AI doesn’t just recall—it analyzes.
Better Research Handling – If knowledge evolves, the AI doesn’t just recall—it analyzes.
![]() More Accurate Code Retrieval – The AI knows when a method is outdated and provides the most relevant solution.
More Accurate Code Retrieval – The AI knows when a method is outdated and provides the most relevant solution.
![]() Stronger Conversations Over Time – No more stale responses—the AI thinks about past interactions in a smarter way.
Stronger Conversations Over Time – No more stale responses—the AI thinks about past interactions in a smarter way.
Kruel.ai was already smart. Now, it’s evolving into something even more powerful:
An AI that doesn’t just remember—it understands.
-This is o3-high project view of the recent changes seeing it gets to look at the code.
The new changes are interesting, we had to run a batch against current memory because we added more properties to the data for the system to understand for the new dynamic weighting. I think this is going to show a major upgrade to its behaviours and ability to understand.
Also understand that this is memory reasoning not the same as the end point COT and its gap / reasoning which is based on the final memory. This may help clarify things further on the design.
Update: I had someone ask me why the response take so long compared to before when we had fast recall. The main difference is in the ai’s self thought process that changed all of that. just to give you an example why sometimes its 25 seconds etc to respond
The total number of AI calls made in this debug log is 55. this is an example of one thought process. 55 GPT call’s to openai model were made during a single message on a friend that included some additional details on what he does for fun.
Even though the thought process added a lot of time the outcomes are worth the extra processing. just like deep research with open ai sometimes is fast sometimes is really deep depending on what you are looking for and how much analysis has to happen.
in code and research in our system they even have more deeper analysis than that general message. which means some research calls could be hundreds of calls depending on the complexity and desired results.
Cost are still pretty low, not as low as they once were haha. at some point I think we had it down to .45 cents / day. but Its scaled a little.
Now some perspective on speed. The online api calls are pretty fast but we will always have latency that we can’t escape based on location, currently the offline models are abit slower but once project digits lands we can offload a large % of the thinking to local models with instant infer speeds which will eliminate the time in the long run which is why we built the system as a hybrid model system so we can support the best options for the tasks at hand.
haha just hope its not like the 5090rtx cards where you can’t get one at any normal price. I really dislike hardware scalper companies. So hopefully the GB10 systems will not be another year away wait for stock. I have a feeling it will be out of stock on release because Ai demand is really high and getting larger every year.
1 Like


- We have integrated the new web search tool directly into the OpenAI pathways of Kruel.ai, replacing the previous KDesk agent method. This enhancement significantly improves research efficiency and online searching when utilizing OpenAI models. For users operating local models, the system will continue to rely on desktop applications. After conducting a deeper cost analysis, I found that the expenses are more manageable than initially expected. My initial assumption was based on a misunderstanding of the pricing structure— As a result, the search functionality with Mini remains just as cost-effective as before. Additionally, by implementing intent-based detection, the system intelligently differentiates between standard queries and those requiring web searches, ensuring that non-search-related requests are processed through the normal model. This allows us to maintain cost control while optimizing performance and efficiency.

What makes this awesome now is that the ai now can learn so much easier from outside. Thanks openai this is a much cleaner and faster approach.
currently I have hard set this model to the mini. We will add options down the road for all models selections to be expanded to all available options as well for offline we will also look at away to provide a lot of options and or possible option to import your own ollama / hugging face compatible models.
for local models we still have Kdesk for outside research which can be setup either to us chrome or the chatgpt desktop.
update:
I have to say this is pretty amazing. @OpenAI_Support Thanks deves you rock ![]()
System Update:
We have recently wiped Linda Prime to perform a necessary update to Neo4j, and we have successfully integrated a functional APOC plugin. Additionally, we have rolled out our Kdoc system, which focuses on document processing and Retrieval-Augmented Generation (RAG). This system enables users to drag and drop files into the message input, which are then processed and uploaded into the memory system via our pre-existing doc_process utility. The integration has been moved to the server-side, streamlining management and improving system performance.
As part of these improvements, we made the decision to remove Llama3.2 Local Mode, as it did not adequately support document processing. In its place, we are testing Mistral-Nemo as the local model, which delivers more accurate results, though at a slightly slower speed due to its larger model size. This is not a significant concern, as our long-term goal involves transitioning to Project DIGITS micro servers, which will support larger models for local operations. We are currently testing the process to ensure smooth integration.
On the client side, OpenAI models continue to perform excellently for these tasks, providing reliable results.
Looking ahead, we still have another key update to implement: multidoc cross-talk within the document system. Since document memory is static and user memory is dynamic, we need to adjust the backend to allow for multi-document understanding. To address this, we plan to employ a multi-step agent to manage tasks such as report generation and multi-document comprehension, ensuring optimal accuracy in processing.
This system update reflects our ongoing commitment to refining the infrastructure for enhanced performance and scalability.
We also recently added a junior to kruel.ai team who is now just learning how to use the ai programmers seeing they only come from a ruby background this should be interesting for them ![]() they join us with zero experience but has been part of the testing of the project.
they join us with zero experience but has been part of the testing of the project.
Lynda prime is back online with all pipelines up and running including the doc system which is in testing
We also added back the openai deep research tool using the vision agent to control the mouse and keyboard to run the openai desktop application. well research and online look ups now happen only on backend for openai model selections in the system. and with the new Mistral-Nemo model instead of llama3.2 we are still using the chatgpt desktop app exclusively as the search tool. This simplifies things for us currently.
on Another path today I am exploring some ideas on NN’s with vision and llm to expand to a multi-step agent that learns than maps out all paths based on experiences to understand what works and what does not based on its understanding to formulate new paths to get there. not sure if I will get this working today, or if it will be a struggle lol
updated relationship tracking

this was rebuilt last night, so its learning pretty fast.
Also understand that each node can carry up to 300MB of data ![]()
3 Likes
*Project Digits, I am aiming for real-time inference on local models. This demonstration leverages the capabilities of ChatGPT O3-High to provide an insightful analysis of kruel.ai from a lighthearted perspective—all while safeguarding our proprietary code. The presentation offers an unbiased comparison of our system with other models in the field. Additionally, I am keen to explore the implications for our final development stages once we integrate enhanced hardware and incorporate a Deepseek or O1–O3 valid thought layer, ultimately guiding us toward our project’s future direction.
Ps. this is a long Zzz chat but will give you better understanding of Kruel.ai
(28min)
Also understand for fun we did a bias perspective to see how it would differ from the un-bias that follows.

Do you store locally? Apologies if this was already answered
Yes, local store, or you could mount a drive , or use a cloud drive etc for store. store affects speed of recall. so would need really fast store ![]()
Do you have a GitHub repo, Discord, or docs where I can learn more about implementation?
Discord
beyond that linkedin and articles online.
1 Like
One more: have you considered multiple LLM integration connecting various APIs into the same chat and allow cross model/company AI real time collaboration?
@j9jv9hmbcz Yes we already do that. We have many stacks of models and api calls for customizations. Well not all can be changed out yet and currently we hard code the models we support to ensure that experience is good. That is not to say that we wont be adding full custom options down the road, but I am not sure yet on what Grok api would look like in our system haha, that would terrify me how that would end in the wrong hands.
The future is still unwritten meaning we can take it any direction or path down the road.
Much like vision system and vocal systems etc will expand further. As well have options to plug in specific instruments and machines to automation and so on down the road.
We have Api input and response out so the goal it to also allow this as middleware.
Something else to show off that we have not in a long time ![]()

Time understanding and memory recall. The system fully understands all memory through time in that you can recall any hour, day, week, year, and between any time you input into the system.
The infer time is based on how much data it has to process and what you specifically request back for outputs as the system has to build all that understanding and the likes.
that will speed up in the future a lot when we get new hardware to go hybrid. also the math will be much faster because that is all local and project digits will allow that to be almost instant and allow us to go much deeper for understanding for pulling clustered information and narrowing.
Project spark not digits any more.. but the Station has now caught my interests.
that would allow over an 800 Billion model to run ![]()
Here’s a more professional version of your update while maintaining clarity and engagement:
Morning Update: System Enhancements and Performance Improvements
As we progress through the week, we are focused on refining our systems, addressing minor bugs, and enhancing overall performance. Below are key updates from last night’s development efforts:
KDesk Vision System Enhancements
- KDesk, our OpenAI ChatGPT desktop application, received additional vision system updates.
- The system now performs multiple validation checks when it cannot identify certain elements, making it more robust in detecting relevant indicators.
- This is still an early-stage implementation, but we are building a strong foundation for a vision-to-action system.
- A notable quirk we observed—if you move the mouse while the AI is controlling it, the system’s step logic starts to counteract the interference, creating an amusing tug-of-war effect.
Chat Window & Markdown Improvements
- Several refinements have been made to the chat interface to enhance usability, particularly for handling large text volumes.
- Drag-and-drop image analysis now includes thumbnail previews for better visual representation.
- We reinstated the AI’s ability to associate names with individuals in images, a feature present in earlier versions.
- This allows users to provide contextual information about people in images, improving the AI’s ability to recognize and retain names in its vision-based memory.
- For example, instead of simply identifying a person in an image, the AI can now describe specific attributes and retain those details for memory-based painting.
Memory Viewer Enhancements
- The Memory Viewer, which had been temporarily removed, has been reinstated.
- It now supports dark theme colors for improved UI consistency and has been optimized for better performance.
Parallel Processing for Memory and Thought Processes
- We introduced parallel processing to both memory functions and cognitive inference.
- Multiple OpenAI and Ollama processes now run concurrently, enhancing the speed of information retrieval and understanding.
- This implementation is temporary until the new AI servers arrive.
- Once deployed, we will offload thought processing to larger, local models, significantly reducing operational costs while dramatically improving inference speed and system efficiency.
These updates are part of our ongoing preparations for integrating DGX equipment, ensuring our system is optimized for enhanced scalability and performance. More updates to follow as development continues.

Site updated ![]()

Announcing Key Enhancements to Our AI Memory System
We’re excited to introduce two significant upgrades designed to improve our AI’s performance and conversational quality:
Self-Monitoring Integration
Our AI now features an advanced self-monitoring mechanism. In essence, the system reviews and refines its own responses in real time, ensuring that the final output is more coherent and contextually accurate. This self-assessment process helps maintain the quality of interactions, enabling the assistant to better understand and adapt to user needs without compromising on responsiveness.
Improved Memory Consolidation
We’ve also enhanced our memory management system. When conversations become extensive, our improved memory consolidation process automatically summarizes and compacts past interactions. This ensures that the assistant retains the most relevant details while keeping the context concise and within operational limits. The result is a more efficient memory retrieval process that supports clearer, faster, and more focused responses.
These upgrades are part of our ongoing efforts to refine user experience by making our system smarter, faster, and more context-aware. We look forward to your feedback as we continue to evolve and enhance our AI capabilities!
New TTS Voice system / Streaming

We added the newest model for voice to replace our previous option which now gives us full emotional ranges through our voice instructions.
There is another system we will be releasing shortly which will be a toggle for dynamic voice where the Ai on the fly based on content will update its instructions on the fly allowing the system to do everything. We will also add in option for on the fly preference editing of the voice instructions which we already have for preferences. This will improve and make the system more exciting and fun.
We are not implementing the new cloud STT models as we currently use the offline whisper model. But that is not to say we won’t offer both we are setup for complete modularity by design.
Also We have completed another 4 certs this week ![]()
Vanderbilt University
- AI Agents and Agentic AI in Python: Powered by Generative AI
Issued: Mar 2025
Credential ID: 0IUB2MDMEK9T
Show Credential - AI Agents and Agentic AI with Python & Generative AI
Issued: Mar 2025
Credential ID: 99203R2IZLSB
Show Credential - Prompt Engineering for ChatGPT
Issued: Mar 2025
Credential ID: H5IKFOC9DXSO
Show Credential
DeepLearning.AI
- Generative Deep Learning with TensorFlow
Issued: Mar 2025
Credential ID: 48RKMRKSKFPB
Show Credential - Advanced Computer Vision with TensorFlow
Issued: Oct 2024
Credential ID: V3Z4R7MUV109
Show Credential - Supervised Machine Learning: Regression and Classification
Issued: Apr 2024
Credential ID: T3DVLQXERMZ2
Show Credential
H2O.ai
- H2O ai Large Language Models (LLMs) - Level 1
Issued: Mar 2025
Credential ID: 03R1A2P92K6D
Show Credential - H2O ai Large Language Models (LLMs) - Level 2
Issued: Mar 2025
Credential ID: JCUDI4KMMMYU
Show Credential - H2O ai Large Language Models (LLMs) - Level 3
Issued: Mar 2025
Credential ID: UFZMQPTH3891
Show Credential - Large Language Models Specialization
Issued: Mar 2025
Credential ID: WDPBO6DI9D79
Show Credential
Neo4j
- Cypher Fundamentals
Issued: May 2024
Credential ID: 3d897b1b-bb55-48d0-afca-5f056d3ae0fe
Show Credential - Graph Data Modeling Fundamentals
Issued: May 2024
Credential ID: f885e7bd-83a6-4bef-a057-99c7663d1bf4
Show Credential - Importing CSV Data into Neo4j
Issued: May 2024
Credential ID: d3e6e622-22a3-4a7a-aea6-da2632ac2397
Show Credential - Neo4j Fundamentals
Issued: May 2024
Credential ID: 69302458-7235-4623-87ed-647a2d7af668
Show Credential - Neo4j & LLM Fundamentals
Issued: Apr 2024
Credential ID: f26c0bc0-d461-4256-8382-5e63c9a1290e
Show Credential
Each certificate is a milestone on our journey through the ever-evolving landscape of AI and data mastery. So, let’s raise a virtual toast to these achievements – proof that when it comes to skills, we’re not just playing around.
3am again?? haha
Could not sleep so updated the preference system fully.
Introduction
In the quest for truly personalized AI, we at Kruel.ai have developed a system that enables real-time behavioral and voice adjustments—all based on simple user instructions. Whether you’re an AI programmer, a voice user interface designer, or just an enthusiast, this new functionality highlights how flexible an AI’s personality and tone can become when the right structures are in place.
What It Does
Our new preference system allows a user to say things like:
- “I want you to sound gently flirty.”
- “Speak in a manic depressed style.”
- “Keep your warm, supportive tone but add comedic timing.”
Then—without pausing or reconfiguring the entire AI—the system seamlessly integrates those changes into the AI’s responses.
How It Benefits AI Programmers
- User-Driven Personalization – Instead of requiring multiple hardcoded modes, developers can let end-users specify or fine-tune the AI’s vibe on demand.
- Instant Updating – Changes occur live, so you don’t have to restart services or push new builds to alter the AI’s behavior or voice.
- Independent Modules – Our system treats textual style and vocal delivery (TTS or otherwise) as distinct layers. That means you can mix and match a given text style with a completely different voice persona if desired.
Use Cases
- Customer Support: Shift from a “strictly formal” voice to a more “empathetic, calming” style in real time, depending on user sentiment.
- Gaming: Players might ask an NPC to become more comedic or adopt a dark, brooding personality mid-session for narrative effect.
- Education: A teaching assistant can pivot between “fun, playful voice” for engaging lessons and “authoritative, no‑nonsense tone” for exams.
Behind the Scenes (Conceptual, No Code!)
- Preferences & Voice – We store each user’s personal style settings and a separate profile for how the AI should deliver its output (speed, tone, comedic flair, etc.).
- Fusion – When a user requests a new trait—like comedic timing or a new accent—the system merges that request with existing instructions, so the updated voice retains anything the user wants to keep (for instance, “gentle tone” or “slow pacing”).
- Security & Filtering – We have safeguards in place to intercept harmful or system-level override commands. If it’s an innocuous style request, we pass it along to the AI. If it’s suspicious, we politely decline.
- Context Awareness – The system references the user’s existing profile and merges only the relevant changes. If someone says, “Add comedic flair,” we keep the old style and just append comedic notes.
The Result: True Flexibility
Users experience an AI that can pivot on a dime, adopting new behaviors and voices with minimal friction. For AI developers, this means fewer “hard-coded modes” and more focus on higher-level logic—your AI can be as whimsical or as professional as the situation demands.
Conclusion
Our dynamic preference system offers AI engineers a powerful new way to deliver personality-rich experiences. By splitting out user preferences and voice instructions into easily updatable components, and applying them in real time, we’ve opened the door to an entirely new class of adaptable, engaging AI interactions—no downtime, no external reconfiguration, just immediate changes in style and voice upon user request.
I am exploring an old system from V2 that we used with the twitch streamer people which allowed full roll playing with voice changing. This I will for sure explore as it was amazing for story telling and games. Not sure when it will be added but its on the ever changing list.
Update on progress ![]()


I have taken my course materials from my Ai education and let Lynda read it all as well it read all the white papers. It has retained everything thus far with no issues. recall has been great. This augments what it knows from knowledge base further to show domain specific learning in real time
Other updates:
We added in a TTS Queue and removed the input blocks allowing continuous inputs each runs on its own process thread.
This now allows for really fast teaching of information through voice or text inputs etc without having to wait for the process to complete ![]()
I have also been looking at the old K6 code, that system was a beast graph knowledge system. I may borrow some of its intelligence and integrate it into our logic stacks to make things even better. There was some pretty optimized stuff in the old system that we don’t have because of the difference on how this system works over the other. But we may find a way to incorporate a new design hybrid. We will see.