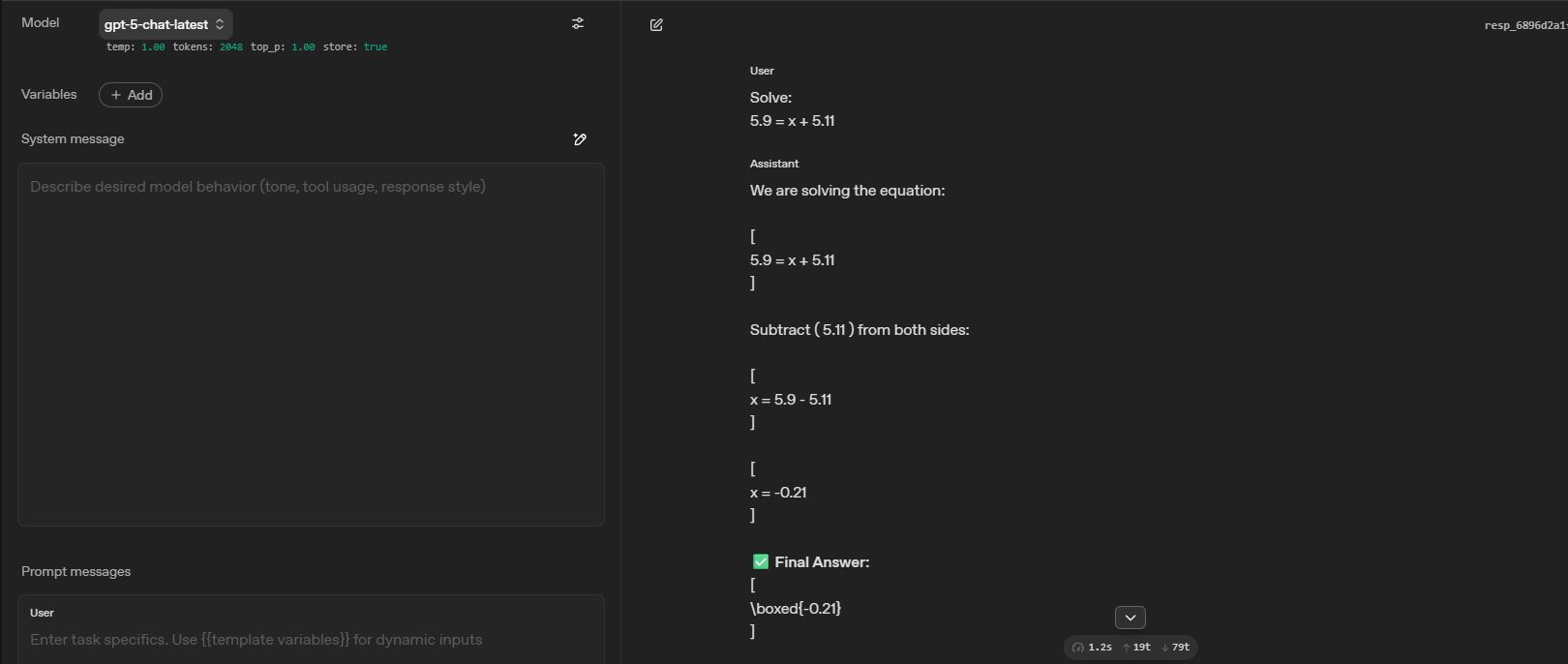
Error only in gpt-5-chat-latest (model) in playground, see screen shot. all other gpt-5 models are correct. any clues


Getting this error too. All other GPT 5 endpoints with minimal reasoning get this correct 80%+, whereas GPT-5-chat-latest gets this right maybe 10-20%. Doesn’t GPT-5-chat-latest route between the GPT-5 endpoints and reasoning levels? It seems to be much worse than any other GPT-5 checkpoint (with reasoning set to minimal).
Ran some benchmarks on this question for the different API endpoints.
gpt-5-chat-latest: 8.0% (4/50)
gpt-5 (minimal): 94.0% (47/50)
gpt-5-mini (minimal): 100.0% (50/50)
gpt-5-nano (minimal): 100.0% (50/50)
Funnily enough having more or less /n (new lines) in the prompt changes gpt-5-chat-latest correct rate on this by a lot. Its always worse, but can get as high with a single line prompt ~45% vs ~10% for a three line prompt. Same exact text just /n between. Something is broken.
1 Like
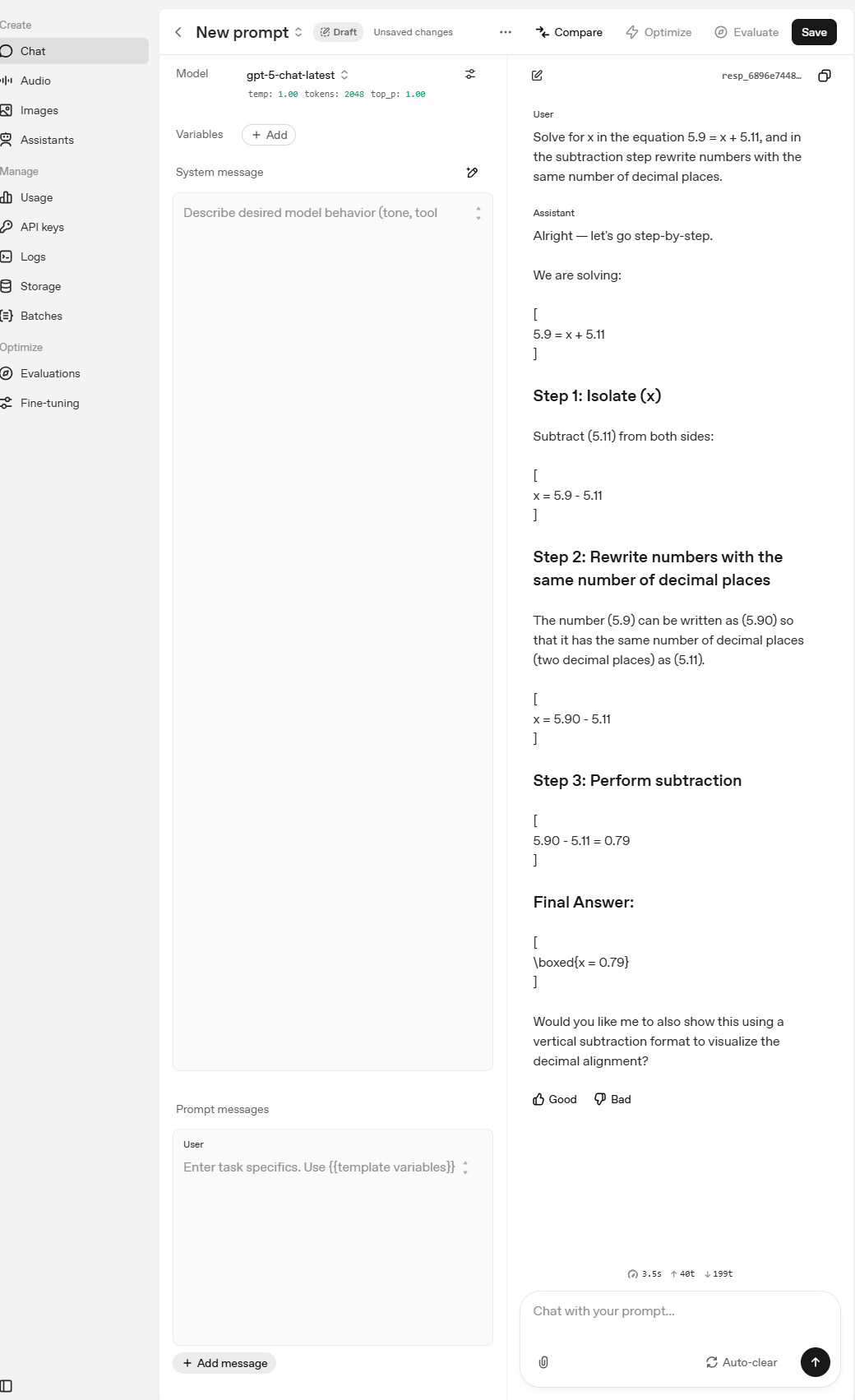
Number tokenization has a unique unjoinable format: 000-999, and then 00-99 and also 0-9.
Let’s unify our fractional part. Plus tell the chat model to knock it off with the LaTeX-ing.
system += Normalize numbers to the same decimal accuracy.
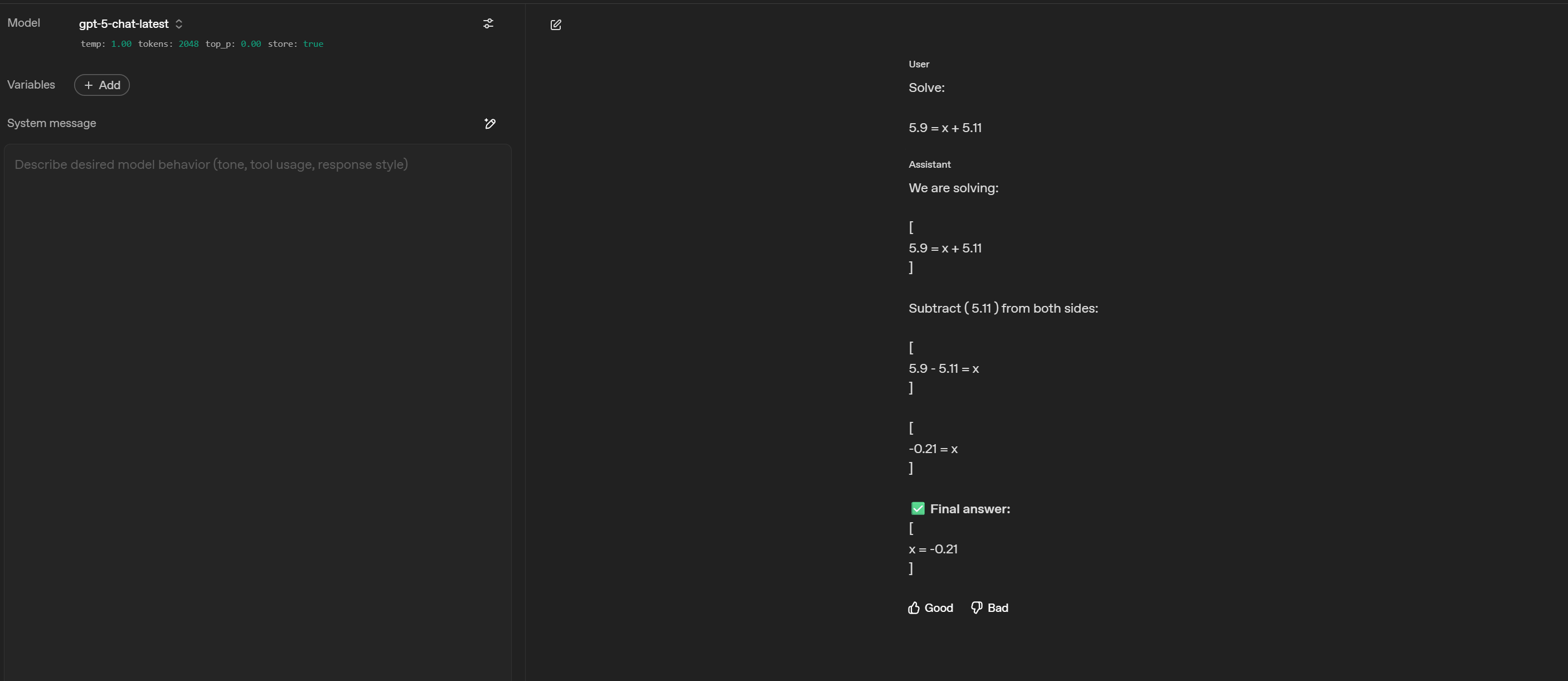
We are solving:
5.9 = x + 5.11
Step 1: Isolate x.
Subtract 5.11 from both sides:x = 5.9 − 5.11
Step 2: Perform the subtraction.
First, write both numbers to the same decimal places:
5.90 − 5.11 = 0.79Step 3: Conclusion:
x = 0.79Final Answer:
x = 0.79
Also, this model allows top_p: 0, no need to run trials against the best prediction path.
top_p still isn’t fully deterministic, right? I still get different answers running the same prompt multiple times with top_p set to 0.
I don’t think giving the model helpful hints should be necessary as even the smallest GPT 5 model set to the lowest reason gets this right nearly every time.
1 Like
Suggestion for Automatic activation of Precise algebraic and Arithmetic reasoning in LLMs:
I would like to propose an enhancement to improve the reliability and accuracy of large language models when handling mathematical expressions, equations, and numeric calculations.
Currently, when presented with equations or numeric problems, LLMs sometimes default to linguistic interpretation rather than strict algebraic or arithmetic evaluation. Also, whenever a user’s textual prompt implies solving a problem that involves composing a mathematical step in the response, even if the user does not explicitly express a mathematical problem.
Proposed Features:
-
Automatic detection of Mathematical contexts:
Enable the model to identify mathematical expressions or numerical inputs and automatically switch to a ‘mathematical reasoning mode’ that prioritises precise, step-by-step algebraic and arithmetic operations. -
Integration with Symbolic computation engines:
Connect LLMs with specialised engines (e.g., Wolfram Alpha, SymPy) or internal numeric libraries to validate and perform exact calculations, ensuring output correctness. -
Default Behavioural shift for Numeric content:
Establish internal system instructions so that whenever numeric or algebraic content is detected, the model defaults to rigorous mathematical reasoning without requiring explicit user prompts.
I believe this is a critical step forward for improving user experience and accuracy in technical domains.
Thank you for considering this suggestion.
1 Like
Are there any ways for us to rollback to the previous version? like the o4-mini-high or o3? This new version cant even process my detailed prompt thoroughly and always ended up dumbing itself
Not on ChatGPT web! ![]()
I miss GPT-4.1 on the web big-time!
This new version just feels… off!
That’s called “code interpreter”, along with “Send python tool scripts to do any calculations, you big math dummy.”
If using gpt-5-chat-latest, no tool for you.
1 Like
Wait what, so they implement a true LLM model mode but don’t give it tools?
You are correct: a true LLM, like davinci-002 on the completions endpoint, has no tools unless you instruct it with dozens of multishot patterns and capture sampling of inference generation to parse out an externally-directed action yourself. Anything else, loaded up with context tokens you don’t control that wrap “messages” sent to an imaginary application-trained sci-fi being - our conditional evaluation on the strict pretense of what constitutes an actual LLM (vs. gpt-5 not being one) - returns “False”.
1 Like
So what is this model for?
1 Like
It tracks:
With a cost and feature and rate limit discouragement.
1 Like
It gets 5.9 - 5.11 wrong but 5.90 - 5.11 correct.
1 Like
What if GPT-5 reads as text and explains “how to get the right answer”?