I gave up on my initial idea and structured my requests differently so that they use vastly less context (but the quality of responses also decreases). A real shame that they don’t care.
And “fraudulent” is a good word. For me it’s been a couple €’s for my testing purposes, but this could have gotten expensive.
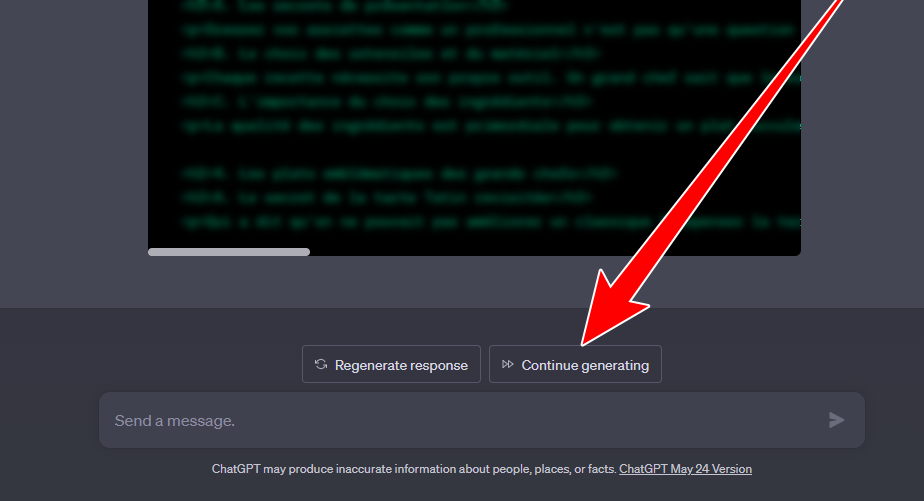
I wonder if there is a connection with the “continue” they deployed on the web version.
Indeed, I think my request is still waiting on the server for a “continue” action, but impossible to do this via the API, since I have no feedback from openAI.
I just have a timeout with an empty result and increased billing to deliver wind…
If so (I have no idea) it should return a response to the API to request a “continue” action, so that it can then deliver the full content…
I don’t think so, this error already occurred weeks before they added this.
And I’m not sure if ChatGPT and the API are comparable in terms of features. You were able to make a “continue” request in the API before that, I believe the frontend of ChatGPT just checks what the reason for ending the response was, and adds that button if it was a premature abortion.
Maybe …
But I find the behavior of the problem very similar, because on the web version, no server return allows to know if yes or no or asks the action to continue, only when clicking on the button, we can see a POST action which allows the server to continue the build.
With the API I think I have the same problem, no return from the server even with a timeout of 600
If this is the case, it would simply be necessary to make a small modification to the API, a return to the state of “break” and a POST on the conversation ID to continue the generation
2 Likes
You know what, you may be on to something.
Maybe it all works out if one uses the streaming api and as soon as an error occurs, fires another request with all the data that was received so far (and everything before that, too, of course).
Bump. Still hoping to get a staff response or official reply here
Does ChatGPT only utilize GPT4? I have the strange feeling that it might also have some embeddings from previos communications (or it just may have been added to training the model or my prompts have changed - it’s just a feeling). I guess we never know.
I mean GPT-4 API Answers differ from chatgpt answers (well, obviously also because the system prompt does something and maybe moderation endpoint when it is triggered it slightly changes the answer?).
Like many projects of this success level, I’m not convinced that anyone at OpenAI actually cares enough to respond to individual developers:( they seem fairly disengaged from my observations of the community.
Same here!! 
In my case, the prompt is super short, actually.
1 Like
Apologies for the delay in my response. I thought the matter was resolved, but I’d like to share my related experiences. Here are some important points to consider:
-
New AI developers should be aware that the maxTokens parameter refers to the total number of tokens in both the request + response. This can become problematic when using the language model to revise/edit text and setting maxTokens to half of the total tokens. If the response exceeds maxTokens/2, the language model will truncate the text without providing any notification. This can be particularly challenging when dealing with very large documents that need to be split into smaller chunks runnig in batches. In such cases, it can be difficult (almost impossible) to identify later where and why text was lost. However, upon reading the resulting text, you may find that nothing seems to be missing.
-
The timeout limit is also a significant issue. Streaming can help in monitoring API actions, but it’s advisable to include a security check by adding the phrase “Place END SESSION at the end of your response.” Into your prompt. This allows you to parse the result text and verify if it constitutes a valid response.
-
Even though extensive testing may have been conducted for your application, it’s important to acknowledge that the model can still produce unpredictable responses in the future, as it has in my case. This unpredictability necessitates caution when relying on completion results in production, particularly when considering large-scale deployment. It’s crucial to note that, in my experience, everything seemed to be running smoothly while editing batches of over 100,000-word texts until sudden erratic behavior occurred. Such unexpected behavior can have a significant and detrimental impact on your startup. While your customers may not directly comprehend the underlying issues originating from the API in the backoffice, the problems they encounter with the results generated by your application can kill the business relationship.
Same issue here…  I didn’t realized before that I was being charged and I put a back-off of 8 times. Now I’m poor.
I didn’t realized before that I was being charged and I put a back-off of 8 times. Now I’m poor.
1 Like
Oh my god, OpenAI finally replied to my support request.
They did so in the most bland, copy-paste way possible. They did not read my problem, they did not check which information I supplied already and gave me some garbage response without any real content:
Hello,
Thank you for reaching out to OpenAI support.
We sincerely apologize that you are encountering the error and for the delay in responding to your message. We’re currently experiencing an unprecedented volume of inbound messages.
Our servers may experience intermittent errors during periods of high traffic, which may affect free users. We recommend trying again in a few minutes or starting a new chat.
You may also try the following:
- Try clearing your browser’s cache and cookies
- Disable VPN (If you are using one)
- Use an incognito browser or a different internet browser/computer to see if the issue still persists, as a security add-in or extension can occasionally cause this type of error.
- Disable cookie blockers
- Try connecting to another network
If the issue persists, kindly provide us with the following information:
- Which specific models are you experiencing this error with (e.g., GPT-4, GPT-3.5)?
- In the past 24 hours, has every attempt within this time period resulted in a “Something went wrong” error?
- Have you tried interacting with the model(s) several times with at least a 24-hour gap between attempts, and encountered the same error each time?
- Any other relevant information
This will help our engineering team troubleshoot the issue.
Best,
LA
OpenAI Support
I wasn’t even talking about ChatGPT, but about the API. And I’m not a free user on ChatGPT either. What the hell man.
Hi Julius,
The https://help.openai.com site is for Account and general help queries, that may be why they did not pick up on the fact it was an API related query.
If the query was related to an account issue with the API then that was the correct place to go and you should respond to the message with more details.
If the query you have is technical in nature then you can post it here, either in a new post topic or update your currently open one if that exists.
Hopefully a solution can be found.
Not sure how any of this information helps.
Yes, the issue is account related, as I’m being billed for no reason.
Yes, the issue is technical in nature. I posted both here (it is literally my thread) and reached out to support.
In my support request I clearly stated what my issue was. Nowhere did I mention ChatGPT, I only talked about the API. And half of the questions they gave me (at least the ones that make sense) were answered already.
Please don’t try to defend this behaviour.
Ok, so the original query was regarding 524 gatewate timeouts, a Cloudflare error where the server took too long to respond, which would potentially be the case for long responses in a beta development environment. What is the reasoning behind not implementing the streaming option to prevent this?
I have yet to thorughly test this scenario (whether streaming + retries truly solve the issue), as my time to experiment has run out. But I’ll get to that eventually.
However, the base issue still exists: If you don’t use streaming and send long requests, you will not get a reply, but you will be billed. And that shouldn’t be the case, really.
Ok, I can see that as valid. My only counter would be that GPT-4 API is in Beta so there will be issues at various levels and with various features. I don’t mean this in any negative way, but engineering is the act of producing real world solution to real world problems and part of that is creating working solutions to beta type issues.
I 100% agree that you should not be charged for a service you have not received in an ideal world, we are however, all super early adopters here and I think we need to take a little time to build around some of the problems that are a pain, but get us firmly established in the brand new science, industry, whatever you want to call it, as pioneers and potentially very well rewarded ones.
Update: I actually received a response from support, and they refunded me $22USD, no idea if that is the correct amount or how they even figured that out. No word if the issue has been fixed or not, haven’t tried it out since.
2 Likes
Closing the loop here, I pinged the team to take a look at this. Overall latency should have improved significantly since this post was originally made. For those who want a response back right way, please try enabling “streaming” mode, which emulates the behavior you see in ChatGPT with responses being “streamed” back in chunks of tokens.
1 Like